
- CPU mediatek 7621AT - a ramips based cpu with 2 cores
- RAM: winbond w632... (too small to read ;)
- flash: 128 MByte NAND winbond w29n01hvsinf
- wifi: ax with a mt7915dan (2T2R 2.4 Ghz, 2T2R 5Ghz) + mt7975dn


I was asked to take a look on a supermicro server which has been damaged by an firmware update. It was an Supermicro X10DRW-IT. The firmware update was tried by USB storage, but somehow failed.
After powering the system, it went like this:
However it seems the IPMI is still booting through and won't be disconnected from the power as the remaining mainboard does, but the IPMI doesn't accept any bios update anymore.
As preparation I read up on the coreboot support for the Supermicro X10SLM+-F [0]
The bios chip is hidden under the raid controller if you've one.

First I've taken a look on the BIOS flash. To read the bios flash out, I've used a raspberry pi 3 with a SOIC-8 clip using the SPI bus.
Required tools:
How you have to connect the SPI SOIC chip is described in [2]. Pin 1 of the SPI chip is where the small hole is on the.
Ensure you Disconnect both power supplies from the mainboard.
sudo flashrom -p linux_spi:dev=/dev/spidev0.0,spispeed=1000 -r bios sudo flashrom -p linux_spi:dev=/dev/spidev0.0,spispeed=1000 -r bios2 sha256sum bios bios2 # ensure the checksum is equal, to ensure you read real things. strings -n 16 bios # try to get some strings out of it, ensure you not only read 0xffff or 0x0000.
Next I downloaded the supermicro bios update. Here you can find:
tree . . ├── DOS │ ├── AFUDOSU.SMC │ ├── CHOICE.SMC │ ├── FDT.smc │ ├── FLASH.BAT │ ├── Readme for X10 AMI BIOS-DOS+UEFI.txt │ └── X10DRW9.B22 └── UEFI ├── Readme for X10 AMI BIOS-DOS+UEFI.txt ├── X10DRW9.B22 ├── afuefi.smc ├── fdt.smc └── flash.nsh ls -al X10DRW9.B22 -rw------- 1 lynxis users 16777216 Nov 22 16:07 X10DRW9.B22
Sound good, it's size is exact 16 MB, the same size as the bios flash. file also tell me what it is.
file X10DRW9.B22
X10DRW9.B22: Intel serial flash for PCH ROM
Great we found a firmware image with ifd (intel firmware descriptor). Now I've looked on the BIOS backup we read with the raspberry pi.
I used hexdump -C bios to see if the end contains a lot of 1s (or 0xffff in hex). Why? Because if you want to write a SPI flash, you can not just write to it like a hard drive. SPI flash chips are organised in blocks. A block is usally 64 kbyte. A single bit on a flash chip can only be written to a 0. If you want to write a single bit with a 1 where a 0 was before (0 -> 1), you've to erase the whole block, not only the address. An erase blocked is full of 1. To find out, if we have a half written flash, we can try to look on the end of the flash if there are a lot of 1s (or 0xffffffff).
hexdump -C is showing it quite nice
00c2ee20 4d 50 44 54 00 01 00 00 10 00 00 00 00 00 10 00 |MPDT............| 00c2ee30 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................| * 01000000
This means, it only written up to 0x00c2ee30 (12.2 MB). Now we can look into the downloaded image, if it looks similiar. Maybe here starts configuration data. But no, it's missing some data here.
Next task is to flash the bios section. Bios section? The intel firmware description contains section. Similiar to a partition layout on a hard drive. On this platform there are 3 different sections
00000000:00000fff fd 00400000:00ffffff bios 00011000:003fffff me
To flash only the partition you either have to use a recent flashrom version (at least 1.0) or you've to extract the layout file using the ifdtool (from coreboot). You can also use the last code snipped as layout.
flashrom -p linux_spi:dev=/dev/spidev0.0,spispeed=1000 -l layout -i bios -w X10DRW9.B22
It verifies it after writing to it. But still it doesn't work. My next thought was maybe the IPMI flash got damaged as well. The SPI flash of the IPMI is close by. So let's have a look. I was lucky to also have a SOIC-16 test clip available. I did the same procedure on the IPMI flash. However the flashrom in raspian was too old. The flash chip wasn't known to this version flashrom. I had to compile it myself.
sudo apt install git build-essential git clone https://review.coreboot.org/flashrom.git cd flashrom make CONFIG_ENABLE_LIBPCI_PROGRAMMERS=no CONFIG_ENABLE_LIBUSB1_PROGRAMMERS=no ./flashrom -p linux_spi:dev=/dev/spidev0.0,spispeed=1000 -r ipmi
But it looks good so far. Running binwalk on it shows us
binwalk ipmi DECIMAL HEXADECIMAL DESCRIPTION -------------------------------------------------------------------------------- 103328 0x193A0 CRC32 polynomial table, little endian 1048576 0x100000 JFFS2 filesystem, little endian 4194304 0x400000 CramFS filesystem, little endian, size: 15216640, version 2, sorted_dirs, CRC 0xB1031FF3, edition 0, 8613 blocks, 1099 files 20971520 0x1400000 uImage header, header size: 64 bytes, header CRC: 0x3F1E0DA5, created: 2019-11-15 08:36:11, image size: 1537512 bytes, Data Address: 0x40008000, Entry Point: 0x40008000, data CRC: 0x310498CA, OS: Linux, CPU: ARM, image type: OS Kernel Image, compression type: gzip, image name: "21400000" 20971584 0x1400040 gzip compressed data, maximum compression, has original file name: "linux.bin", from Unix, last modified: 2019-11-15 07:25:15 24117248 0x1700000 CramFS filesystem, little endian, size: 7458816, version 2, sorted_dirs, CRC 0xF5B9463B, edition 0, 3108 blocks, 466 files
Looks also good, however I want to be sure, it's the fine. I did first a backup, second overwritten with a file from the IPMI firmware update.
Still no change.
So what's wrong here? Is the power management controller damaged? The power supply are controller digital via I2C. Maybe it's somehow telling me something is wrong?
I was lucky, I didn't had a i2c sniffer around, otherwise I would have digged into it. I nearly gave it up, before I found out, that the backup file didn't worked with ifdtool. I exported the layout using the firmware update file, and not with the backup file. Usually firmware updates do not touch the ifd. It seems server boards are different. So the backup didn't contained an ifd. It wasn't only damaged in the end, also in the beginning. Not sure if this is a safety feature of the update. It might ensure at the beginning of an update the partial flash wouldn't be recognized as a working image. It's not a good thing booting a half working image.
I flashed the bios firmware update image and the board is back. To be sure, I flashed the ipmi backup on the SPI chip.
TLDR; So the fast way to recover a partial bios, do a backup first! Then flash the full image. At least for this generation it works.
Note: Depending on your specific hardware setup (cable length, test clip) you can increase or decrease the spispeed. spispeed=10000 => 10 MHz should be still ok. You'll notice the wrong spispeed if the reading or flashing fails.
[0] https://doc.coreboot.org/mainboard/supermicro/x10slm-f.html
[1] https://www.pomonaelectronics.com/products/test-clips/soic-clip-8-pin
[2] https://github.com/bibanon/Coreboot-ThinkPads/wiki/Hardware-Flashing-with-Raspberry-Pi
Similiar to lolamby' regular post on his free software contribution, I want to start a similiar post.
The big chunk of the December I prepared together with the GSM team the celluar network at the 36c3 (36. Chaos Communication Congress). Every year we're building our own celluar network using free software project osmocom & open5gs. Osmocom is a community project around mobile communication. We used osmocom to run our core network (CN) of our 2G and 3G network. Open5gs is our LTE CN, which was interconnected to the osmocom CN. Here is a overview, every buble is an own daemon.
The 36c3 was a nice testing ground. We had to extend a couple of the services (e.g. osmomsc, osmogsup2dia, osmohnbgw). While the event we also like to enjoy the congress, so this is our excuse to not upstream our patches right a away. However we push our branches as it is to https://git.osmocom.org. Upstreaming will be more seen in January.
Last week I visited thomasdotwtf from eventphone who has a jura coffee machine. We took one evening to look into it, how easy it is, to use a generic BLE device like a raspberry pi to control it. He has a Jura Z8 Automatic Coffee Machine which supports an IOS/Android app via Bluetooh LE.
Jura released (at least) two different apps to control it.
Both apps supports ordering, changing properties of a coffee (e.g. how much water do you want to have or how much coffee should be in there?). mkssystems.pl seems to went out-of-service, but the internet archive still have an old version and they show a lot of coffee machine related products. As well as a small blue device [1].
This is the BlueFrog a bluetooth dongle to control Jura coffee machines.
- bluetooth packettrace: We used the android btsnoop.log to retrieve a packet trace which we loaded into wireshark.
- decompiled with different tools the .apk
- loaded the source code into android studio
The J.O.E. application is using XML files to be configured for the different coffee machines. The XML defines products (e.g. a coffee, a green tea, ...), there are properties (e.g. how much coffee should be produced), statistics and settings. The article number defines the XML file to be used.
A firmware process including the update urls and the new firmware.
We tried to find the same commands which should work on the RS232/serial in the bluetooth packet trace, but there wasn't any. After looking further in the code, we found a lot UUIDs for characteristics including a human readable name. We discovered also an "encryption" method which uses 2x hardcoded keys as well an additional input of 8 bit from the BLE advertisment. The encryption look like a static key.
In the BLE advertisment, there are manufactoring data. In our case, the manufactoring data contains 27 bytes. If 16 bit will be used, it's little endian.
manufactoring data as hex (27 byte): aa 05 06 03 d73a yyyy xxxx 5836 4435 01 c0 00 00 00 00 00 00 00 00 00 00 00 aa: key 05: BlueFrog Major Version 06: BlueFrog Minor Version 03: unused (maybe Patch Version?) d73a: article number (the specific type of the machine) yyyy: machine number xxxx: serial number 5836: production date (Feb. 2017) 4435: production date UHCI (does UHCI means the bluefrog?) (Okt. 2016) 01: unused c0: bitmask, define supported features
The production dates can be decoded and also validated using the application where it's shown in the connection fragment:
days: (i & 31) month: ((i & 480) >> 5) year: ((i & 65024) >> 9) + 1990;
Write a decrypt function which can parse pcap files and shows the message or write a dissector (lua) for wireshark with decryption function.
Find out how to map the XML files into commands towards the BlueFrog.
The good thing of BLE is, it's standarzied in the communication. BLE uses Bluetooth Attribute Protocol to communicate. The Bluetooth Attribute Protocol uses services and characteristics. A service is an object which can hold multiple characteristics. A characteristic can support one or more of the following operations read, write, notification, indication. Every service has a UUID as well a characteristic has a UUID. The Bluetooth Attribute Protocol has it's own methods to discover avaiable services and characterics. For more information please take a closer look into Bluetooth Low Energy.
As a general BLE device, the BlueFrog annouce itself on the BLE.
> hcitool lescan
LE Scan ...
C9:26:E8:4B:72:02 TT214H BlueFrog
> HCI Event: LE Meta Event (0x3e) plen 43 #8 [hci0] 8.466202
LE Advertising Report (0x02)
Num reports: 1
Event type: Scan response - SCAN_RSP (0x04)
Address type: Random (0x01)
Address: C9:26:E8:4B:72:02 (Static)
Data length: 31
Company: Ingenieur-Systemgruppe Zahn GmbH (171)
Data: aa050603d73a080402005836443501c00000000000000000000000
RSSI: -78 dBm (0xb2)
And further more we can also look for the services and characteristics via the gatttool.
> gatttool -b C9:26:E8:4B:72:02 --services -t random attr handle = 0x0001, end grp handle = 0x0007 uuid: 00001800-0000-1000-8000-00805f9b34fb attr handle = 0x0008, end grp handle = 0x0008 uuid: 00001801-0000-1000-8000-00805f9b34fb attr handle = 0x0009, end grp handle = 0x0033 uuid: 5a401523-ab2e-2548-c435-08c300000710 attr handle = 0x0034, end grp handle = 0x003a uuid: 5a401623-ab2e-2548-c435-08c300000710 attr handle = 0x003b, end grp handle = 0xffff uuid: 00001530-1212-efde-1523-785feabcd123
> gatttool -b C9:26:E8:4B:72:02 --characteristics -t random handle = 0x0002, char properties = 0x0a, char value handle = 0x0003, uuid = 00002a00-0000-1000-8000-00805f9b34fb handle = 0x0004, char properties = 0x02, char value handle = 0x0005, uuid = 00002a01-0000-1000-8000-00805f9b34fb handle = 0x0006, char properties = 0x02, char value handle = 0x0007, uuid = 00002a04-0000-1000-8000-00805f9b34fb handle = 0x000a, char properties = 0x02, char value handle = 0x000b, uuid = 5a401524-ab2e-2548-c435-08c300000710 handle = 0x000d, char properties = 0x08, char value handle = 0x000e, uuid = 5a401525-ab2e-2548-c435-08c300000710 handle = 0x0010, char properties = 0x08, char value handle = 0x0011, uuid = 5a401529-ab2e-2548-c435-08c300000710 handle = 0x0013, char properties = 0x08, char value handle = 0x0014, uuid = 5a401528-ab2e-2548-c435-08c300000710 handle = 0x0016, char properties = 0x0a, char value handle = 0x0017, uuid = 5a401530-ab2e-2548-c435-08c300000710 handle = 0x0019, char properties = 0x02, char value handle = 0x001a, uuid = 5a401527-ab2e-2548-c435-08c300000710 handle = 0x001c, char properties = 0x02, char value handle = 0x001d, uuid = 5a401531-ab2e-2548-c435-08c300000710 handle = 0x001f, char properties = 0x0a, char value handle = 0x0020, uuid = 5a401532-ab2e-2548-c435-08c300000710 handle = 0x0022, char properties = 0x0a, char value handle = 0x0023, uuid = 5a401535-ab2e-2548-c435-08c300000710 handle = 0x0025, char properties = 0x0a, char value handle = 0x0026, uuid = 5a401533-ab2e-2548-c435-08c300000710 handle = 0x0028, char properties = 0x02, char value handle = 0x0029, uuid = 5a401534-ab2e-2548-c435-08c300000710 handle = 0x002b, char properties = 0x02, char value handle = 0x002c, uuid = 5a401536-ab2e-2548-c435-08c300000710 handle = 0x002e, char properties = 0x02, char value handle = 0x002f, uuid = 5a401537-ab2e-2548-c435-08c300000710 handle = 0x0031, char properties = 0x02, char value handle = 0x0032, uuid = 5a401538-ab2e-2548-c435-08c300000710 handle = 0x0035, char properties = 0x02, char value handle = 0x0036, uuid = 5a401624-ab2e-2548-c435-08c300000710 handle = 0x0038, char properties = 0x08, char value handle = 0x0039, uuid = 5a401625-ab2e-2548-c435-08c300000710 handle = 0x003c, char properties = 0x04, char value handle = 0x003d, uuid = 00001532-1212-efde-1523-785feabcd123 handle = 0x003e, char properties = 0x18, char value handle = 0x003f, uuid = 00001531-1212-efde-1523-785feabcd123
| start | end | uuid | name | |
|---|---|---|---|---|
| 0x0001 | 0x0007 | 0x1800 | Generic Access Profile | |
| 0x0008 | 0x0008 | 0x1801 | Generic Attribute Profile | |
| 0x0009 | 0x0033 | 5a401523-ab2e-2548-c435-08c300000710 | ||
| 0x0034 | 0x003a | 5a401623-ab2e-2548-c435-08c300000710 | ||
| 0X003b | 0xffff | 00001530-1212-efde-1523-785feabcd123 |
| handle | value handle | properties | uuid | description |
|---|---|---|---|---|
| 0x0002 | 0x0003 | RW (0xa) | 00002a00-0000-1000-8000-00805f9b34fb | |
| 0x0004 | 0x0005 | R (0x2) | 00002a01-0000-1000-8000-00805f9b34fb | |
| 0x0006 | 0x0007 | R (0x2) | 00002a04-0000-1000-8000-00805f9b34fb |
| handle | value handle | properties | uuid | description |
|---|---|---|---|---|
| 0x000a | 0x000b | R (0x2) | 5a401524-ab2e-2548-c435-08c300000710 | Machine Status |
| 0x000d | 0x000e | W (0x8) | 5a401525-ab2e-2548-c435-08c300000710 | Product Start |
| 0x0010 | 0x0011 | W (0x8) | 5a401529-ab2e-2548-c435-08c300000710 | Service Control |
| 0x0013 | 0x0014 | W (0x8) | 5a401528-ab2e-2548-c435-08c300000710 | Update Product Progress |
| 0x0016 | 0x0017 | RW (0xa) | 5a401530-ab2e-2548-c435-08c300000710 | Product Progress |
| 0x0019 | 0x001a | R (0x2) | 5a401527-ab2e-2548-c435-08c300000710 | About |
| 0x001c | 0x001d | R (0x2) | 5a401531-ab2e-2548-c435-08c300000710 | |
| 0x001f | 0x0020 | RW (0xa) | 5a401532-ab2e-2548-c435-08c300000710 | |
| 0x0022 | 0x0023 | RW (0xa) | 5a401535-ab2e-2548-c435-08c300000710 | |
| 0x0025 | 0x0026 | RW (0xa) | 5a401533-ab2e-2548-c435-08c300000710 | Statistics command |
| 0x0028 | 0x0029 | R (0x2) | 5a401534-ab2e-2548-c435-08c300000710 | Statistics data |
| 0x002b | 0x002c | R (0x2) | 5a401536-ab2e-2548-c435-08c300000710 | |
| 0x002e | 0x002f | R (0x2) | 5a401537-ab2e-2548-c435-08c300000710 | |
| 0x0031 | 0x0032 | R (0x2) | 5a401538-ab2e-2548-c435-08c300000710 | Service Control Response |
| handle | value handle | properties | uuid | description |
|---|---|---|---|---|
| 0x0035 | 0x0036 | R (0x2) | 5a401624-ab2e-2548-c435-08c300000710 | |
| 0x0038 | 0x0039 | W (0x8) | 5a401625-ab2e-2548-c435-08c300000710 |
| handle | value handle | properties | uuid | description |
|---|---|---|---|---|
| 0x003c | 0x003d | W- (0x4) | 00001532-1212-efde-1523-785feabcd123 | Nordic DFU_PACKET_CHARACTERISTI |
| 0x003e | 0x003f | W N (0x18) | 00001531-1212-efde-1523-785feabcd123 | Nordic DFU_CONTROL_POINT_CHARACTERISTIC |

I joined the MirageOS retreat in March 2019. It's an 1 week event in Marrakech, Marocco. It's a real nice house in the old city of Marrakech, the medina. The event itself doesn't have much structure than a morning meeting and sometimes talks in the evening.
MirageOS is unikernel written in OCaml. MirageOS can run ontop of many backends, e.g. Unix process or xen, kvm, bhyve. This retreat I took care of the Internet uplink. We had a slow and leaky 4MBit ADSL line from Marocco Telecom which we used as backup, while using LTE as main uplink. We used first imwi as provider. But imwi changes the IPs quites often and the implementation in OpenWrt uqmi does not follow the IP changes, which resulted in a stale LTE connection. Imwi is also filtering all UDP DNS queries, except those going to their own servers. We then switched to Orange as provider, because someone had a card available. Orange was fast enough, pretty stable 5MBit up&down. We consumed roughly 20 GB a day. This brought us the nice daily ritual, a walk to a small and nice mobile shop in the medina. 1 GB cost 10 Dh (1 Euro). Our router, an APU2, runs OpenWrt, but we disabled DNS & DHCP and ran these services on a seperate APU using MirageOS.
Even I'm not such familiar with OCaml and functional languages, I tried to fix a bug in the DHCP Server implementation PR#97. It worked for me, however after deploying it, it turned out, it only worked for me, I broke it for everybody else ;). This motivated me to start looking on TTCN-3, a ETSI language to test network protocols. Later together with Hannes, we fixed the DHCP for real. Adding some TTCN-3 tests and create a simple base is still on my TODO. Another really nice OCaml service on side was a learn-ocaml instance. An interactive teaching web application for beginners and advances OCaml programmers including an annotate OCaml compiler. Sadly there is no instance in the internet yet, as the projects is not ready for release.
While there I also worked a lot on reproducible builds for OpenWrt. I fixed 2 packages. All OpenWrt base packages are 100 % reproducible. Thanks to Daniel Golle, OpenWrt images can be cryptographically signed. This signature must be removed before looking for differences, this is also done in the reproducible builds setup for OpenWrt. 100% of ar71xx images are reproducible and 98% of ramips. The remaining 2% are also signature problems, but these signatures are in the middle instead of the end of the image. I also found the time to integrate my package index parser into reproducible builds. It's much easier to just parse two packages list, than looking on the all package files to determine if they are reproducible or not. The package index files also contain metadata of the packages which it inserts into the reproducible builds database.
Some people from the QubesOS projects joined the retreat. For example there is a MirageOS firewall which replaces the QubesOS own one. There is also a Pong game, which can run as QubesOS-vm. Thanks to the QubesOS people for their help on my problems with disposable vms.
Furthermore I brought a beaglebone black with me to investigate bugs reported for that platform. While looking at it, I found out the last release of OpenWrt (18.06.2) doesn't work on this board (fs: squashfs), while master works. I also fixed builds issues with u-boot in OpenWrt for the beaglebone black when using a modern toolchain.
Since we used LTE as uplink, we wanted to know how much of our data volume was consumed. OpenWrt might have statistics, but those are stored only in memory and not saved anywhere. I didn't looked for any OpenWrt packages which fixes this problem, because the provider (Orange) is supporting a USSD code to retrieve the remaining volume.
What is USSD? USSD stands for Unstructured Supplementary Service Data. It's used on mobile phones to retrieve balance, your phone number, your IMEI, [..]. Most people have used them. Take your phone, open the phone application and call *#06#, it will return your phone unique identifier (IMEI). While SMS is a store-and-forward scheme, like email. USSD is real time message protocol, similiar to a TCP connection. The USSD codes are simple, do a request, get a response. Done. But Orange implemented a menu via USSD. So the USSD session will look like: Request, Response, Choose Your Menu, Response, Go Back, Choose different Point. I've started writing USSD support for libqmi. Simple USSD codes can be requested and decoded, but not menus with user input.
And the biggest problem is: OpenWrt doesn't support USSD at all. Not even the simple ones.
Sometimes, when I'm not directly around or I forgot to put the powersupply into my laptop. My laptop runs into the critical power action. Because I'm using upowerd, my machine try to does this:
Great! My machine shuts down, in the middle of doing something. It would take 2 minutes to get a powersupply, but too late!!
But there might be a solution for this: Suspend. My machine can survive more than 1 hour in suspend with this low battery.
It would help me NOT loosing my current unsaved work.
After looking into the upowerd, it's just a 1 line code change to allow this. It is not a good default, but there are people who like to use this.
But .. upowerd doesn't like. They not even want to allow the user to take this option. Indepentent that I agree, this shouldn't be the default. We're discussing this issue for years. Without any solution. Upowerd want to decide what users should do with there laptop and what not.
How to resolve it?
From time to time you need to test things with the old image. But how do you test thing when the original build environment is lost and you want to test sysuprade against this old release (actually 12.09).
First you've to create a flashdump of the firmware paritition.
# grep firmware /proc/mtd mtd5: 003d0000 00010000 "firmware" # ssh root@192.168.1.1 dd if=/dev/mtd5 > /tmp/firmware_backup
Afterwards you can use binwalk to get the actual offsets of the different parts inside.
# binwalk /tmp/firmware_backup DECIMAL HEXADECIMAL DESCRIPTION -------------------------------------------------------------------------------- 512 0x200 LZMA compressed data, properties: 0x6D, dictionary size: 8388608 bytes, uncompressed size: 2813832 bytes 930352 0xE3230 Squashfs filesystem, little endian, version 4.0, compression:xz, size: 2194094 bytes, 728 inodes, blocksize: 262144 bytes, created: 2014-03-05 14:58:48 3145728 0x300000 JFFS2 filesystem, big endian
So sysupgrade images for ar71xx is still using the (old) layout of
---------- |KERNEL | ---------- |squashfs| ---------- |jffs2 | ----------
While a sysupgrade image contains for those platforms:
-------------- |KERNEL | -------------- |squashfs | -------------- |jffs2-dummy | --------------
So we will split-off the jffs2 Part and replace it with jffs2.
# dd if=/tmp/firwmare_backup bs=3145728 count=1 of=/tmp/sysupgrade.img
Next we add this jffs2-dummy by using the same tool LEDE is using it:
# /home/lynxis/lede/staging_dir/host/bin/padjffs2 /tmp/sysupgrade.img 64
The 64 means the padding size in kb. It's important to choose the right one, but for most devices this is 64k at least for ar71xx.
ssh root@192.168.1.1 dd if=/dev/mtd5 > /tmp/firmware_backup binwalk /tmp/firmware_backup dd if=/tmp/firwmare_backup bs=3145728 count=1 of=/tmp/sysupgrade.img /home/lynxis/lede/staging_dir/host/bin/padjffs2 /tmp/sysupgrade.img 64
A friend gave me the his x1 carbon gen1 some time ago. The x1 carbon is little bit different from other Thinkpad because it's a combination of a Thinkpad and a Ultrabook.
Looking under the hood. The x1 carbon gen1 look very likely as x230.


A graphic can describe a thing more than 1000 words. This is how mksquashfs 4.3 works.
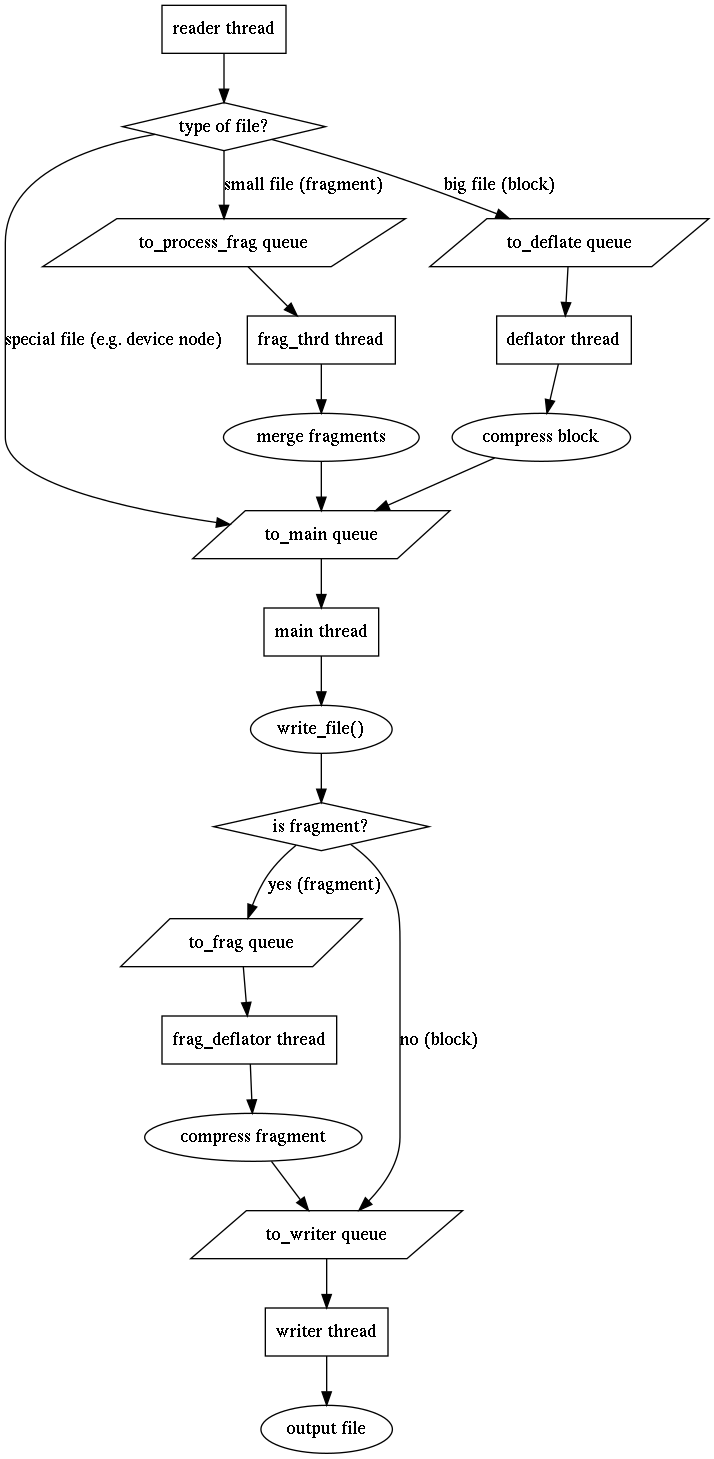
This howto will get your through a LEDE to create your own kernel patch using the LEDE infrastructure. It's based on LEDE reboot-1279-gc769c1b.
LEDE has already a lot of patches. They are all applied on one tree. We will create a new patch for lantiq. To get started, let see how LEDE organize the patches. First of all we take a look on /target/linux/*
All of these folders represent a architecture target, except generic. The generic target is used by all targets.
To continue, we need to know which kernel version your target architecture is running on. This is written down into target/linux/lantiq/Makefile.
We're running a 4.4.Y kernel. The Y is written down into /include/kernel-version.mk. We will use .15.
Ok. Now let's see. When LEDE is preparing the kernel build directory, it search for a matching patch directory.
But which is the right patches directory? It use the following make snippet from /include/kernel.mk
Meaning it will use /patches-4.4 if exists or if not try to use /patches.
Now we know how patches are applied to the linux kernel tree. We could go into the directory, create a new patches directory and use quilt...
Or we use the quilt target for that.
make target/linux/clean -> to clean up the old directory. Now make target/linux/prepare QUILT=1 will unpack the source, copy all present patches into ./patches and use quilt to apply.
With quilt you can move forwards and backwards between patches, aswell as modifying those. cd ./build_dir/target-mips_34kc+dsp_uClibc-0.9.33.2/linux-lantiq/linux-4.5.15/ to switch into the linux directory.
Your modification is under ./build_dir/../linux-4.4.15/patches/platform/. With make target/linux/refresh it will refresh all patches and copy them to the correct folder under target/linux/*/patches.
The TP-Link CPE510, a nice outdoor device, got a bad rx behaviour when using it with LEDE. I want to give a short overview how to debug those problems. It could also help you finding problems when facing ath9k pci cards.
To get down to the device. The CPE510 based on a AR9344 SoC. The integrated wireless part is supported by the ath9k driver. To get more knowledge about the AR9344 you should take a look into the public available datasheet. (google for ar9344 datasheet ;)
The AR9344 supports using GPIOs for special purposes it's called a GPIO function. If the function is enabled, the gpio is internally routed to the special purpose. Now the simple part comes if you know which register to look into, just look into it.
After reading the pages 52/53 of the datasheet, it's clear that it can route everything signal to every gpio. Remember the table, because it explains what value means what it's routed to the gpio. We suggest LNA are missing because the receiving part of the CPE510 is bad. So the value 46 and 47 are the important ones, 46 LNA Chain 0, 47 LNA Chain 1. LNA stands for low noice amplifier.
Now we know how the GPIOs works, let's find the register controlling the GPIO function. The GPIO section start at 130, but the interesting part is the GPIO IO Function 0 register at address 0x1804002c. It give you 8 bit to describe it's function, if it's 0x0 no function is selected and the GPIO is used as normal output. So if you write 46 into the bit 0-7 you set the GPIO to become the LNA Chain 0 signal. Every GPIO from GPIO0 to GPIO19 can configured using those register.
We know what registers are interesting (0x1804002c - 0x1804003c). We know which values are interesting (decimal 46 and decimal 47).
But how can we read out those value from a running system? First answer I hear is JTAG, but JTAG isn't easy to archive and more difficult to use on ar71xx, because the bootloader usally deactivate JTAG as one of the first commands.
But we can ask the kernel. /dev/mem is quite usefull for that. It's a direct way to the memory, very dangerous, but also handy ;). The easiest way to interface with /dev/mem is the simple utility called devmem or devmem2. To compile a compatible devmem2 you should use the GPL sources of the firmware, but you can also download the binary from here [1].
Copy devmem2 to /tmp via scp and start reading the values. Because mips is a 32bit architecture we have to read the register
Back to our LNA value. 46 and 47. In hex are those 0x2E and 0x2F. We have to look for those values aligned to 8bit.
# ./devmem2 0x1804002c /dev/mem opened. Memory mapped at address 0x2aaae000. Value at address 0x1804002C (0x2aaae02c): 0x0 # ./devmem2 0x18040030 /dev/mem opened. Memory mapped at address 0x2aaae000. Value at address 0x18040030 (0x2aaae030): 0xB0A0900 # ./devmem2 0x18040034 /dev/mem opened. Memory mapped at address 0x2aaae000. Value at address 0x18040034 (0x2aaae034): 0x2D180000 # ./devmem2 0x18040038 /dev/mem opened. Memory mapped at address 0x2aaae000. Value at address 0x18040038 (0x2aaae038): 0x2C # ./devmem2 0x1804003c /dev/mem opened. Memory mapped at address 0x2aaae000. Value at address 0x1804003C (0x2aaae03c): 0x2F2E0000 #
Found it in 0x1804003C. LNA 0 is GPIO 18 and LNA1 is GPIO 19.
Since long time ago I was inspired of the features of LAVA (Linaro Automated Validation). Lava was developed by Linaro to do automatic test on real hardware. It's written in python and based on a lot small daemons and one django application. It's scheduling submitted tests on hardware depending on the rights and availability. Setting up an own instance isn't so hard, there is an video howto. But Lava is changing it's basic device model to pipeline devices to make it more flexible because the old device model was quite limited. Our instance is available under https://lava.coreboot.org. Atm. there is only one device (x60) and we're looking for help to add more devices.
coreboot is under heavy development around 200 commits a month. Sometime breaks, most time because somebody refactored code and made it simpler. There are many devices supported by coreboot, but commits aren't tested on every hardware. Which means it broke on some hardware. And here the bisect loop begins.
Lava is the perfect place to do bisecting. You can submit a Testjob via commandline, track Job and wait until it's done. Lava itself takes cares that a job doesn't take to long. To break down the task into smaller peaces:
- checkout a revision
- compile coreboot
- copy artefact somewhere where Lava can access it (http-server)
- submit a lava testjob
- lava deploys your image and do some tests
git-bisect does the binary search for the broken revision, checks out the next commit which needs to be tested. But somebody have to tell git-bisect if this is a good or bad revision. Or you use git bisect run. git bisect run a small script and uses the return code to know if this is a good or bad revision. There is also a third command skip, to skip the revision if the compilation fails. git-bisect would do the full bisect job, but to use lava, it needs a Lava Test Job. Under https://github.com/lynxis/coreboot-lava-bisect is my x60 bisect script together with a Lava Test Job for the x60. It only checks if coreboot is booting. But you might want to test something else. Is the cdrom is showing up? Is the wifi card properly detected? Checkout the lava documentation for more information about how to write a Lava Testjob or a Lava Test.
To communicate with Lava on the shell you need to have lava-tool running on your workstation. See https://validation.linaro.org/static/docs/overview.html
With lava-tool submit-job $URL job.yml you can submit a job and get the JobId. And check the status of your job with lava-tool job-status $URL $JOBID. Depending on the job-status the script must set the exit code. My bisect script for coreboot is https://github.com/lynxis/coreboot-lava-bisect
cd coreboot # CPU make -j$CPU export CPU=4 # your login user name for the lava.coreboot.org # you can also use LAVAURL="https://$LAVAUSER@lava.coreboot.fe80.eu/RPC2" export LAVAUSER=lynxis # used by lava to download the coreboot.rom export COREBOOTURL=https://fe80.eu/bisect/coreboot.rom # used as a target by *scp* export COREBOOT_SCP_URL=lynxis@fe80.eu:/var/www/bisect/coreboot.rom git bisect start git bisect bad <REV> git bisect good <REV> git bisect run /path/to/this/dir/bisect.sh
All roads lead to Rome, but PulseAudio is not far behind! In fact, how the PulseAudio client library determines how to try to connect to the PulseAudio server has no less than 13 different steps. Here they are, in priority order:
1) As an application developer, you can specify a server string in your call to pa_context_connect. If you do that, that’s the server string used, nothing else.
2) If the PULSE_SERVER environment variable is set, that’s the server string used, and nothing else.
3) Next, it goes to X to check if there is an x11 property named PULSE_SERVER. If there is, that’s the server string, nothing else. (There is also a PulseAudio module called module-x11-publish that sets this property. It is loaded by the start-pulseaudio-x11 script.)
4) It also checks client.conf, if such a file is found, for the default-server key. If that’s present, that’s the server string.
So, if none of the four methods above gives any result, several items will be merged and tried in order.
First up is trying to connect to a user-level PulseAudio, which means finding the right path where the UNIX socket exists. That in turn has several steps, in priority order:
5) If the PULSE_RUNTIME_PATH environment variable is set, that’s the path.
6) Otherwise, if the XDG_RUNTIME_DIR environment variable is set, the path is the “pulse” subdirectory below the directory specified in XDG_RUNTIME_DIR.
7) If not, and the “.pulse” directory exists in the current user’s home directory, that’s the path. (This is for historical reasons – a few years ago PulseAudio switched from “.pulse” to using XDG compliant directories, but ignoring “.pulse” would throw away some settings on upgrade.)
8) Failing that, if XDG_CONFIG_HOME environment variable is set, the path is the “pulse” subdirectory to the directory specified in XDG_CONFIG_HOME.
9) Still no path? Then fall back to using the “.config/pulse” subdirectory below the current user’s home directory.
Okay, so maybe we can connect to the UNIX socket inside that user-level PulseAudio path. But if it does not work, there are still a few more things to try:
10) Using a path of a system-level PulseAudio server. This directory is /var/run/pulse on Ubuntu (and probably most other distributions), or /usr/local/var/run/pulse in case you compiled PulseAudio from source yourself.
11) By checking client.conf for the key “auto-connect-localhost”. If so, also try connecting to tcp4:127.0.0.1…
12) …and tcp6:[::1], too. Of course we cannot leave IPv6-only systems behind.
13) As the last straw of hope, the library checks client.conf for the key “auto-connect-display”. If it’s set, it checks the DISPLAY environment variable, and if it finds a hostname (i e, something before the “:”), then that host will be tried too.
To summarise, first the client library checks for a server string in step 1-4, if there is none, it makes a server string – out of one item from steps 5-9, and then up to four more items from steps 10-13.
And that’s all. If you ever want to customize how you connect to a PulseAudio server, you have a smorgasbord of options to choose from!
This one’s going to be a bit of a long post. You might want to grab a cup of coffee before you jump in!
Over the last few years, I’ve spent some time getting PulseAudio up and running on a few Android-based phones. There was the initial Galaxy Nexus port, a proof-of-concept port of Firefox OS (git) to use PulseAudio instead of AudioFlinger on a Nexus 4, and most recently, a port of Firefox OS to use PulseAudio on the first gen Moto G and last year’s Sony Xperia Z3 Compact (git).
The process so far has been largely manual and painstaking, and I’ve been trying to make that easier. But before I talk about the how of that, let’s see how all this works in the first place.
If you have managed to get by without having to dig into this dark pit, the porting process can be something of an exercise in masochism. More so if you’re in my shoes and don’t have access to any of the documentation for the audio hardware. Hardware vendors and OEMs usually don’t share these specifications unless under NDA, which is hard to set up as someone just hacking on this stuff as an experiment or for fun in their spare time.
Broadly, the task involves looking at how the devices is set up on Android, and then replicating that process using the standard ALSA library, which is what PulseAudio uses (this works because both the Android and generic Linux userspace talk to the same ALSA-based kernel audio drivers).
First, you look at the Android audio HAL code for the device you’re porting, and the corresponding mixer paths XML configuration. Between the two of these, you get a description of how you can configure the hardware to play back audio in various use cases (music, tones, voice calls), and how to route the audio (headphones, headset, speakers, Bluetooth).
 Snippet from mixer paths XML
Snippet from mixer paths XML
In this example, there is one path that describes how to set up the hardware for “deep buffer playback” (used for music, where you can buffer a bunch of data and let the CPU go to sleep). The next path, “speaker”, tells us how to set up the routing to play audio out of the speaker.
These strings are not well-defined, so different hardware uses different path names and combinations to set up the hardware. The XML configuration also does not tell us a number of things, such as what format the hardware supports or what ALSA device to use. All of this information is embedded in the audio HAL code.
Next, you need to translate this configuration into something PulseAudio will understand1. The preferred method for this is ALSA’s UCM, which describes how to set up the hardware for each use case it supports, and how to configure the routing in each of those use cases.
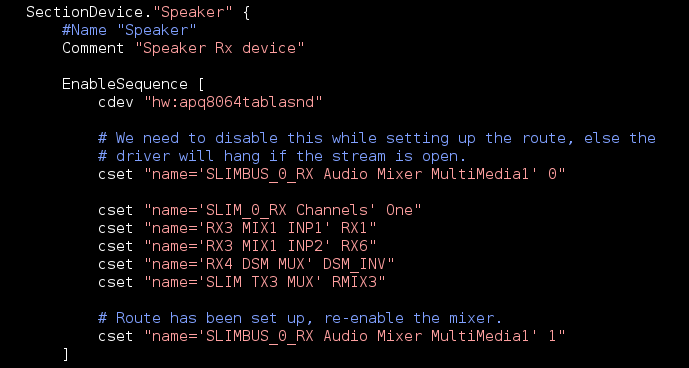 Snippet from UCM
Snippet from UCM
This is a snippet from the “hi-fi” use case, which is the UCM use case roughly corresponding to “deep buffer playback” in the previous section. Within that, we’re looking at the “speaker device” and you can see the same mixer controls as in the previous XML file are toggled. This file does have some additional information — for example, this snippet specifies what ALSA device should be used to toggle mixer controls (“hw:apq8064tablasnd”).
Typically, I start with the “hi-fi” use case — what you would normally use for music playback (and could likely use for tones and such as well). Getting the “phone” use case working is usually much more painful. In addition to setting up the audio hardware similar to th “hi-fi use case, it involves talking to the modem, for which there isn’t a standard method across Android devices. To complicate things, the modem firmware can be extremely sensitive to the order/timing of setup, often with no means of debugging (a.k.a. fun times!).
When there is a new Android version, I need to look at all the changes in the HAL and the XML file, redo the translation to UCM, and then test everything again.
This is clearly repetitive work, and I know I’m not the only one having to do it. Hardware vendors often face the same challenge when supporting the same devices on multiple platforms — Android’s HAL usually uses the XML config I showed above, ChromeOS’s CrAS and PulseAudio use ALSA UCM, Intel uses the parameter framework with its own XML format.
With this background, when I started looking at the Z3 Compact port last year, I decided to write a tool to make this and future ports easier. That tool is creatively named xml2ucm2.
As we saw, the ALSA UCM configuration contains more information than the XML file. It contains a description of the playback and mixer devices to use, as well as some information about configuration (channel count, primarily). This information is usually hardcoded in the audio HAL on Android.
To deal with this, I introduced a small configuration file that provides the additional information required to perform the translation. The idea is that you write this configuration once, and can more or less perform the translation automatically. If the HAL or the XML file changes, it should be easy to implement that as a change in the configuration and just regenerate the UCM files.
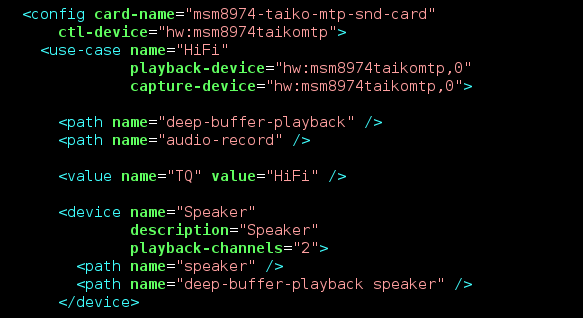 Example xml2ucm configuration
Example xml2ucm configuration
This example shows how the Android XML like in the snippet above can be converted to the corresponding UCM configuration. Once I had the code done, porting all the hi-fi bits on the Xperia Z3 Compact took about 30 minutes. The results of this are available as a more complete example: the mixer paths XML, the config XML, and the generated UCM.
One big missing piece here is voice calls. I spent some time trying to get voice calls working on the two phones I had available to me (the Moto G and the Z3 Compact), but this is quite challenging without access to hardware documentation and I ran out of spare time to devote to the problem. It would be nice to have a complete working example for a device, though.
There are other configuration mechanisms out there — notably Intel’s parameter framework. It would be interesting to add support for that as well. Ideally, the code could be extended to build a complete model of the audio routing/configuration, and generate any of the configuration that is supported.
I’d like this tool to be generally useful, so feel free to post comments and suggestions on Github or just get in touch.
p.s. Thanks go out to Abhinav for all the Haskell help!
Another approach, which the Ubuntu Phone and Jolla SailfishOS folks take, is to just use the Android HAL directly from PulseAudio to set up and use the hardware. This makes sense to quickly enable any arbitrary device (because the HAL provides a hardware-independent interface to do so). In the longer term, I prefer to enable using UCM and alsa-lib directly since it gives us more control, and allows us to use such features as PulseAudio’s dynamic latency adjustment if the hardware allows it. ↩
You might have noticed that the tool is written in Haskell. While this is decidedly not a popular choice of language, it did make for a relatively easy implementation and provides a number of advantages. The unfortunate cost is that most people will find it hard to jump in and start contributing. If you have a feature request or bug fix but are having trouble translating it into code, please do file a bug, and I would happy to help! ↩
Happy 2016 everyone!
While I did mention a while back (almost two years ago, wow) that I was taking a break, I realised recently that I hadn’t posted an update from when I started again.
For the last year and a half, I’ve been providing freelance consulting around PulseAudio, GStreamer, and various other directly and tangentially related projects. There’s a brief list of the kind of work I’ve been involved in.
If you’re looking for help with PulseAudio, GStreamer, multimedia middleware or anything else you might’ve come across on this blog, do get in touch!
2.1 surround sound is (by a very unscientific measure) the third most popular surround speaker setup, after 5.1 and 7.1. Yet, ALSA and PulseAudio has since a long time back supported more unusual setups such as 4.0, 4.1 but not 2.1. It took until 2015 to get all pieces in the stack ready for 2.1 as well.
The problem
So what made adding 2.1 surround more difficult than other setups? Well, first and foremost, because ALSA used to have a fixed mapping of channels. The first six channels were decided to be:
1. Front Left
2. Front Right
3. Rear Left
4. Rear Right
5. Front Center
6. LFE / Subwoofer
Thus, a four channel stream would default to the first four, which would then be a 4.0 stream, and a three channel stream would default to the first three. The only way to send a 2.1 channel stream would then be to send a six channel stream with three channels being silence.
This was not good enough, because some cards, including laptops with internal subwoofers, would only support streaming four channels maximum.
(To add further confusion, it seemed some cards wanted the subwoofer signal on the third channel of four, and others wanted the same signal on the fourth channel of four instead.)
ALSA channel map API
The first part of the solution was a new alsa-lib API for channel mapping, allowing drivers to advertise what channel maps they support, and alsa-lib to expose this information to programs (see snd_pcm_query_chmaps, snd_pcm_get_chmap and snd_pcm_set_chmap).
The second step was for the alsa-lib route plugin to make use of this information. With that, alsa-lib could itself determine whether the hardware was 5.1 or 2.1, and change the number of channels automatically.
PulseAudio bass / treble filter
With the alsa-lib additions, just adding another channel map was easy.
However, there was another problem to deal with. When listening to stereo material, we would like the low frequencies, and only those, to be played back from the subwoofer. These frequencies should also be removed from the other channels. In some cases, the hardware would have a built-in filter to do this for us, so then it was just a matter of setting enable-lfe-remixing in daemon.conf. In other cases, this needed to be done in software.
Therefore, we’ve integrated a crossover filter into PulseAudio. You can configure it by setting lfe-crossover-freq in daemon.conf.
The hardware
If you have a laptop with an internal subwoofer, chances are that it – with all these changes to the stack – still does not work. Because the HDA standard (which is what your laptop very likely uses for analog audio), does not have much of a channel mapping standard either! So vendors might decide to do things differently, which means that every single hardware model might need a patch in the kernel.
If you don’t have an internal subwoofer, but a separate external one, you might be able to use hdajackretask to reconfigure your headphone jack to an “Internal Speaker (LFE)” instead. But the downside of that, is that you then can’t use the jack as a headphone jack…
Do I have it?
In Ubuntu, it’s been working since the 15.04 release (vivid). If you’re not running Ubuntu, you need alsa-lib 1.0.28, PulseAudio 7, and a kernel from, say, mid 2014 or later.
Acknowledgements
Takashi Iwai wrote the channel mapping API, and also provided help and fixes for the alsa-lib route plugin work.
The crossover filter code was imported from CRAS (but after refactoring and cleanup, there was not much left of that code).
Hui Wang helped me write and test the PulseAudio implementation.
PulseAudio upstream developers, especially Alexander Patrakov, did a thorough review of the PulseAudio patch set.
We just rolled out a minor bugfix release. Quick changelog:
More details on the mailing list.
Thanks to everyone who contributed with bug reports and testing. What isn’t generally visible is that a lot of this happens behind the scenes downstream on distribution bug trackers, IRC, and so forth.
I know it’s been ages, but I am now working on updating the webrtc-audio-processing library. You might remember this as the code that we split off from the webrtc.org code to use in the PulseAudio echo cancellation module.
This is basically just the AudioProcessing module, bundled as a standalone library so that we can use the fantastic AEC, AGC, and noise suppression implementation from that code base. For packaging simplicity, I made a copy of the necessary code, and wrote an autotools-based build system around that.
Now since I last copied the code, the library API has changed a bit — nothing drastic, just a few minor cleanups and removed API. This wouldn’t normally be a big deal since this code isn’t actually published as external API — it’s mostly embedded in the Chromium and Firefox trees, probably other projects too.
Since we are exposing a copy of this code as a standalone library, this means that there are two options — we could (a) just break the API, and all dependent code needs to be updated to be able to use the new version, or (b) write a small wrapper to try to maintain backwards compatibility.
I’m inclined to just break API and release a new version of the library which is not backwards compatible. My rationale for this is that I’d like to keep the code as close to what is upstream as possible, and over time it could become painful to maintain a bunch of backwards-compatibility code.
A nicer solution would be to work with upstream to make it possible to build the AudioProcessing module as a standalone library. While the folks upstream seemed amenable to the idea when this came up a few years ago, nobody has stepped up to actually do the work for this. In the mean time, a number of interesting features have been added to the module, and it would be good to pull this in to use in PulseAudio and any other projects using this code (more about this in a follow-up post).
So if you’re using webrtc-audio-processing, be warned that the next release will probably break API, and you’ll need to update your code. I’ll try to publish a quick update guide when releasing the code, but if you want to look at the current API, take a look at the current audio_processing.h.
p.s.: If you do use webrtc-audio-processing as a dependency, I’d love to hear about it. As far as I know, PulseAudio is the only user of this library at the moment.
This one’s a bit late, for reasons that’ll be clear enough later in this post. I had the happy opportunity to go to GUADEC in Gothenburg this year (after missing the last two, unfortunately). It was a great, well-organised event, and I felt super-charged again, meeting all the people making GNOME better every day.
 GUADEC picnic @ Gothenberg
GUADEC picnic @ Gothenberg
I presented a status update of what we’ve been up to in the PulseAudio world in the past few years. Amazingly, all the videos are up already, so you can catch up with anything that you might have missed here.
We also had a meeting of PulseAudio developers which and a number of interesting topics of discussion came up (I’ll try to summarise my notes in a separate post).
A bunch of other interesting discussions happened in the hallways, and I’ll write about that if my investigations take me some place interesting.
Now the downside — I ended up missing the BoF part of GUADEC, and all of the GStreamer hackfest in Montpellier after. As it happens, I contracted dengue and I’m still recovering from this. Fortunately it was the lesser (non-haemorrhagic) version without any complications, so now it’s just a matter of resting till I’ve recuperated completely.
Nevertheless, the first part of the trip was great, and I’d like to thank the GNOME Foundation for sponsoring my travel and stay, without which I would have missed out on all the GUADEC fun this year.
I was in Depok, Indonesia last week to speak at GNOME Asia 2015. It was a great experience — the organisers did a fantastic job and as a bonus, the venue was incredibly pretty!
 View from our room
View from our room
My talk was about the GNOME audio stack, and my original intention was to talk a bit about the APIs, how to use them, and how to choose which to use. After the first day, though, I felt like a more high-level view of the pieces would be more useful to the audience, so I adjusted the focus a bit. My slides are up here.
Nirbheek and I then spent a couple of days going down to Yogyakarta to cycle around, visit some temples, and sip some fine hipster coffee.
All in all, it was a week well spent. I’d like to thank the GNOME Foundation for helping me get to the conference!
Some friends give me their old hardware to help me on my next project: Create an open source embedded controller firmware for Lenovo Thinkpads. My target platform are all Lenovo Thinkpads using a Renesas/Hitachi H8S as EC. These chips built into Thinkpads from very old one to new models like the X230.
So what can be better that using a very old laptop like a T40 to solder and do hardware mods? The first step is flashing the chip independent from the Operating System running on the hardware. Why that? Because the EC controls certain power regulators and take care of turning the mainboard on. A broken EC would allow you to turn your Laptop on. The H8S supports different boot modes. It can boot normal advance boot. The boot mode is a special mode for developing and flashing. It receive their firmware over normal UART and execute it. The H8S defines it boot mode over 2 pins - MD0 and MD1 - also named mode0 and mode1. After looking on the schematics (which is available on the internet) we need to solder the UART pin RX, TX, MD1, GND. MD0 isn't required, because it's already set to 0. I soldered the test pin TP1, TP10 (I2C). /RES was soldered too, because I miscounted the pins. /RES lies beside of MD1. But it can be useful later. I colored the pins on the bottom picture.
| color | pin |
| Red | MD1 |
| Orange | GND |
| Blue | /RES |
| Green | RX |
| Yellow | TX |



The soldered image is missing MD1.
I got the task to setup LACP witch an not so new 3com siwtch on one side and a Debian Jessie + OpenVSwitch on the other. Usally not a so big problem. Just keep in mind, 3com was bought by HP and is still using 3com software in their newer products. It's even possible to update an 3com switch with HP firmware if you're lucky to know which HP product matches your HP switch. Back to the task: setup LACP. I've done everything mentioned in the manual: Check all ports are the same media type All ports must be configured in the same way * have the same LACP priority
Everything seems be ok. The documentation also say that all Ports will loose their individual port conifiguration when added. On the switch side I can see the switch is showing my Linux Box as port partner, but still the link group isn't going into 'Active' state. Still showing 'The port is not configured properly.'. An update is not a option from remote, to much service depends on this switch. Let's take a closer look on the VLAN configuration. The LACP group isn't configured yet for any VLAN. But the ports still have an old configuration with tagged VLAN and is in hybrid mode? Why? It has a PVID configured, but not an untagged vlan asigned. Looks strange.
Go to VLAN -> Modify Port: Select both LACP ports as well as the LACP group and set them into Trunk mode without any VLAN. Now the LACP changed to active. Maybe this changed in newer HP firmware versions.
This is a technical post about PulseAudio internals and the upcoming protocol improvements in the upcoming PulseAudio 6.0 release.
PulseAudio is said to have a “zero-copy” architecture. So let’s look at what copies and buffers are involved in a typical playback scenario.
When PulseAudio server and client runs as the same user, PulseAudio enables shared memory (SHM) for audio data. (In other cases, SHM is disabled for security reasons.) Applications can use pa_stream_begin_write to get a pointer directly into the SHM buffer. When using pa_stream_write or through the ALSA plugin, there will be one memory copy into the SHM.
On the server side, the server might need to convert the stream into a format that fits the hardware (and potential other streams that might be running simultaneously). This step is skipped if deemed unnecessary.
First, the samples are converted to either signed 16 bit or float 32 bit (mainly depending on resampler requirements).
In case resampling is necessary, we make use of external resampler libraries for this, the default being speex.
Second, if remapping is necessary, e g if the input is mono and the output is stereo, that is performed as well. Finally, the samples are converted to a format that the hardware supports.
So, in worst case, there might be up to four different buffers involved here (first: after converting to “work format”, second: after resampling, third: after remapping, fourth: after converting to hardware supported format), and in best case, this step is entirely skipped.
PulseAudio’s built in mixer multiplies each channel of each stream with a volume factor and writes the result to the hardware. In case the hardware supports mmap (memory mapping), we write the mix result directly into the DMA buffers.
The best we can do is one copy in total, from the SHM buffer directly into the DMA hardware buffer. I hope this clears up any confusion about what PulseAudio’s advertised “zero copy” capabilities means in practice.
However, memory copies is not the only thing you want to avoid to get good performance, which brings us to the next point:
PulseAudio does pretty well CPU wise for high latency loads (e g music playback), but a bit worse for low latency loads (e g VOIP, gaming). Or to put it another way, PulseAudio has a low per sample cost, but there is still some optimisation that can be done per packet.
For every playback packet, there are three messages sent: from server to client saying “I need more data”, from client to server saying “here’s some data, I put it in SHM, at this address”, and then a third from server to client saying “thanks, I have no more use for this SHM data, please reclaim the memory”. The third message is not sent until the audio has actually been played back.
For every message, it means syscalls to write, read, and poll a unix socket. This overhead turned out to be significant enough to try to improve.
So instead of putting just the audio data into SHM, as of 6.0 we also put the messages into two SHM ringbuffers, one in each direction. For signalling we use eventfds. (There is also an optimisation layer on top of the eventfd that tries to avoid writing to the eventfd in case no one is currently waiting.) This is not so much for saving memory copies but to save syscalls.
From my own unscientific benchmarks (i e, running “top”), this saves us ~10% – 25% of CPU power in low latency use cases, half of that being on the client side.
The third week of October was quite action-packed, with a whole bunch of conferences happening in Düsseldorf. The Linux audio developer community as well as the PulseAudio developers each had a whole day of discussions related to a wide range of topics. I’ll be summarising the events of the PulseAudio mini summit day here. The discussion was split into two parts, the first half of the day with just the current core developers and the latter half with members of the community participating as well.
I’d like to thank the Linux Foundation for sparing us a room to carry out these discussions — it’s fantastic that we are able to colocate such meetings with a bunch of other conferences, making it much easier than it would otherwise be for all of us to converge to a single place, hash out ideas, and generally have a good time in real life as well!
 Happy faces — incontrovertible proof that everyone loves PulseAudio!
Happy faces — incontrovertible proof that everyone loves PulseAudio!
With a whole day of discussions, this is clearly going to be a long post, so you might want to grab a coffee now. :)
We have a few blockers for 6.0, and some pending patches to merge (mainly HSP support). Once this is done, we can proceed to our standard freeze → release candidate → stable process.
For simplifying packaging, it would be nice to be able to build all the available BlueZ module backends in one shot. There wasn’t much opposition to this idea, and David (Henningsson) said he might look at this. (as I update this before posting, he already has)
We briefly discussed plans around the recently introduced shared ringbuffer channel code for communication between PulseAudio clients and the server. We talked about the performance benefits, and future plans such as direct communication between the client and server-side I/O threads.
Tanu (Kaskinen) has a long-standing set of patches to add a generic routing framework to PulseAudio, developed by notably Jaska Uimonen, Janos Kovacs, and other members of the Tizen IVI team. This work adds a set of new concepts that we’ve not been entirely comfortable merging into the core. To unblock these patches, it was agreed that doing this work in a module and using a protocol extension API would be more beneficial. (Tanu later did a demo of the CLI extensions that have been made for the new routing concepts)
As a consequence of the discussion around the routing framework, David mentioned that he’d like to take forward Colin’s priority list work in the mean time. Based on our discussions, it looked like it would be possible to extend module-device-manager to make it port aware and get the kind functionality we want (the ability to have a priority-order list of devices). David was to look into this.
Relatedly, we discussed the need to export the PA internal headers to allow externally built modules. We agreed that this would be okay to have if it was made abundantly clear that this API would have absolutely no stability guarantees, and is mostly meant to simplify packaging for specialised distributions.
Which led us to the other bit of infrastructure required to write modules more easily — making our protocol extension mechanism more generic. Currently, we have a static list of protocol extensions in our core. Changing this requires exposing our pa_tagstruct structure as public API, which we haven’t done. If we don’t want to do that, then we would expose a generic “throw this blob across the protocol” mechanism and leave it to the module/library to take care of marshalling/unmarshalling.
Alexander shared a number of his findings about resampler quality on PulseAudio, vs. those found on Windows and Mac OS. Some questions were asked about other parameters, such as relative CPU consumption, etc. There was also some discussion on how to try to carry this work to a conclusion, but no clear answer emerged.
It was also agreed on the basis of this work that support for libsamplerate and ffmpeg could be phased out after deprecation.
The discussion came around to the possibility of having a mode where (if the hardware supports it), PulseAudio just plays out samples without resampling, conversion, etc. This has been brought up in the past for “audiophile” use cases where the card supports 88.2/96 kHZ and higher sample rates.
No objections were raised to having such a mode — I’d like to take this up at some point of time.
Alexander has some code for filtering low frequencies for the LFE channel, currently as a virtual sink, that could eventually be integrated into the core.
David raised a question about the current status of rtkit and whether it needs to exist, and if so, where. Lennart brought up the fact that rtkit currently does not work on systemd+cgroups based setups (I don’t seem to have why in my notes, and I don’t recall off the top of my head).
The conclusion of the discussion was that some alternate policy method for deciding RT privileges, possibly within systemd, would be needed, but for now rtkit should be used (and fixed!)
Discussions came up about the possibility of using kdbus and/or memfd for the PulseAudio transport. This is interesting to me, there doesn’t seem to be an immediately clear benefit over our SHM mechanism in terms of performance, and some work to evaluate how this could be used, and what the benefit would be, needs to be done.
David has now submitted patches for controls that affect multiple outputs (such as “Headphone+LO”). These are currently being discussed.
Tanu would like to add code to support collecting audio streams into “audio groups” to apply collective policy to them. I am supposed to help review this, and Colin mentioned that module-stream-restore already uses similar concepts.
Tanu proposed the addition of new objects to represent streams and objects. There didn’t seem to be consensus on adding these, but there was agreement of a clear need to consolidate common code from sink-input/source-output and sink/source implementations. The idea was that having a common parent object for each pair might be one way to do this. I volunteered to help with this if someone’s taking it up.
Alexander brough up the need for a filter API in PulseAudio, and this is something I really would like to have. I am supposed to sketch out an API (though implementing this is non-trivial and will likely take time).
David plans to see if we can use profile availability to help determine when an HDMI device is actually available.
The usability of flat-volumes for browser use cases (where the volume of streams can be controlled programmatically) was discussed, and my patch to allow optional opt-out by a stream from participating in flat volumes came up. Tanu and I are to continue the discussion already on the mailing list to come up with a solution for this.
Alexander raised concerns about the quality of rewinding code in some of our filter modules. The agreement was that we needed better documentation on handling rewinds, including how to explicitly not allow rewinds in a sink. The example virtual sink/source code also needs to be adjusted accordingly.
Wim Taymans’ work on adding back HSP support to PulseAudio came up. Since the meeting, I’ve reviewed and merged this code with the change we want. Speaking to Luiz Augusto von Dentz from the BlueZ side, something we should also be able to add back is for PulseAudio to act as an HSP headset (using the same approach as for HSP gateway support).
Takashi Iwai raised a question about what a good way to run PA in a container was. The suggestion was that a tunnel sink would likely be the best approach.
Based on discussion from the previous day at the Linux Audio mini-summit, I’m supposed to look at the possibility of consolidating the various mixer configuration formats we currently have to deal with (primarily UCM and its implementations, and Android’s XML format).
(thanks to Tanu, David and Peter for reviewing this)
There are lot of howtos written for this topic but most won't worked for me. Irky's howto is very good. I'm mirroring his files here and summarise his howto. If you have any question look into his article.
The dockstar is special device, because it does not support serial boot like other Marvel kirkwood devices. E.g. when you bricked a Seagate GoFlex you can recover it without jtag over serial boot. What is serial boot? Recover without jtag
This howto is for the Seagate Dockstar tested on archlinux with openocd 0.8!
You need only a buspirate with a jtag firmware, no serial is needed here.
openocd -f dockstar.cfgsheevaplug_initnand probe 0nand erase 0 0x0 0xa0000nand write 0 uboot.j.kwb 0 oob_softecc_kwHeadsets come in many sorts and shapes. And laptops come with different sorts of headset jacks – there is the classic variant of one 3.5 mm headphone jack and one 3.5 mm mic jack, and the newer (common on smartphones) 3.5 mm headset jack which can do both. USB and Bluetooth headsets are also quite common, but that’s outside the scope for this article, which is about different types of 3.5 mm (1/8 inch) jacks and how we support them in Ubuntu 14.04.
You’d think this would be simple to support, and for the classic (and still common) version of having one headphone jack and one mic jack that’s mostly true, but newer hardware come in several variants.
If we talk about the typical TRRS headset – for the headset itself there are two competing standards, CTIA and OMTP. CTIA is the more common variant, at least in the US and Europe, but it means that we have laptop jacks supporting only one of the variants, or both by autodetecting which sort has been plugged in.
Speaking of autodetection, hardware differs there as well. Some computers can autodetect whether a headphone or a headset has been plugged in, whereas others can not. Some computers also have a “mic in” mode, so they would have only one jack, but you can manually retask it to be a microphone input.
Finally, a few netbooks have one 3.5 mm TRS jack where you can plug in either a headphone or a mic but not a headset.
So, how would you know which sort of headset jack(s) you have on your device? Well, I found the most reliable source is to actually look at the small icon present next to the jack. Does it look like a headphone (without mic), headset (with mic) or a microphone? If there are two icons separated by a slash “/”, it means “either or”.
For the jacks where the hardware cannot autodetect what has been plugged in, the user needs to do this manually. In Ubuntu 14.04, we now have a dialog:

In previous versions of Ubuntu, you would have to go to the sound settings dialog and make sure the correct input and output were selected. So still solvable, just a few more clicks. (The dialog might also be present in some Ubuntu preinstalls running Ubuntu 12.04.)
So in userspace, we should be all set. Now let’s talk about kernels and individual devices.
Quite common with Dell machines manufactured in the last year or so, is the version where the hardware can’t distinguish between headphones and headsets. These machines need to be quirked in the kernel, which means that for every new model, somebody has to insert a row in a table inside the kernel. Without that quirk, the jack will work, but with headphones only.
So if your Dell machine is one of these and not currently supporting headset microphones in Ubuntu 14.04, here’s what you can do:
Notes for people not running Ubuntu
Four years and what seems like a lifetime ago, I jumped aboard the ship Collabora Multimedia, and set sail for adventure and lands unknown. We sailed through strange new seas, to exotic lands, defeated many monsters, and, I feel, had some positive impact on the world around us. Last Friday, on my request, I got dropped back at the shore.
I’ve had an insanely fun time at Collabora, working with absurdly talented and dedicated people. Nevertheless, I’ve come to the point where I feel like I need something of a break. I’m not sure what’s next, other than a month or two of rest and relaxation — reading, cycling, travel, and catching up with some of the things I’ve been promising to do if only I had more time. Yes, that includes PulseAudio and GStreamer hacking as well. :-)
And there’ll be more updates and blog posts too!
The Sailfish xmpp client integrates perfect into your contacts, but doesn't work with your own jabber server as long you are using self-signed certificate. This is because SailfishOS even checks per default the server certificate, which is great! But there is no GUI to add you own CA or certificate, so you don't get any connection to an server which uses an unknown certificate. IMHO commercial Certificate Authority are broken by design, but that's another story :). The usual answer for a working jabber is disable the certificate check for your xmpp. You are disabling every feature of ssl (which is not much as long over hundrets of CA are in your chain). With checking you have a little bit more secury than nothing. As alternative you can add the certificates to the telepathy chain. The jabber client (telepathy-gabble) have an additional folder of certificates. telepathy add certificates from /home/nemo/.config/telepathy/certs/ before loading all certificates from /etc/pki/tls/certs/ca-bundle.crt. Just put it into that folder.
# mkdir -p /home/nemo/.config/telepathy/certs/
# cp /home/nemo/Downloads/jabber-ca_or_cert.crt /home/nemo/.config/telepathy/certs/
I've re-added my jabber account to make the certificate work. :Maybe a reboot will apply your certificate as well.
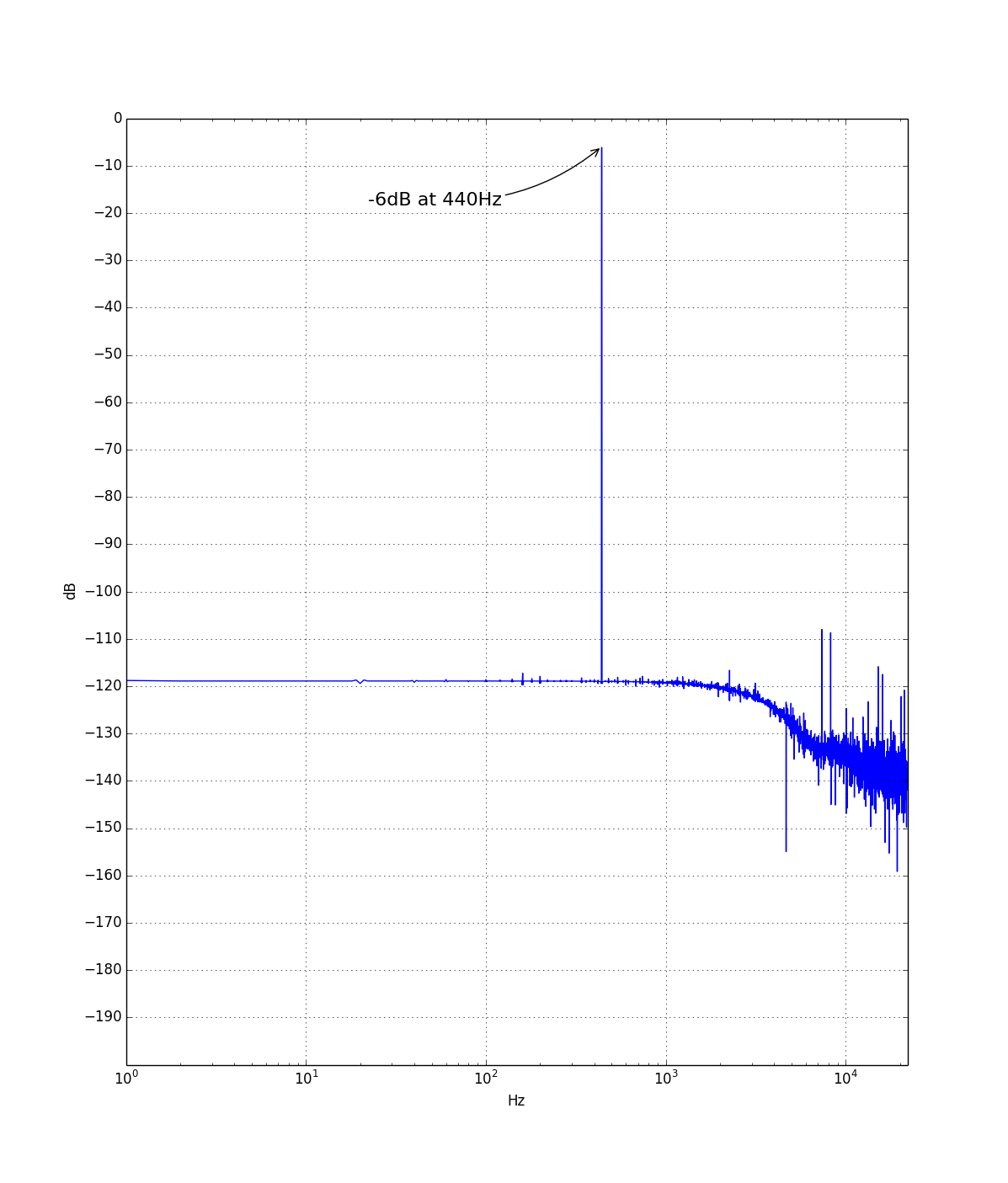
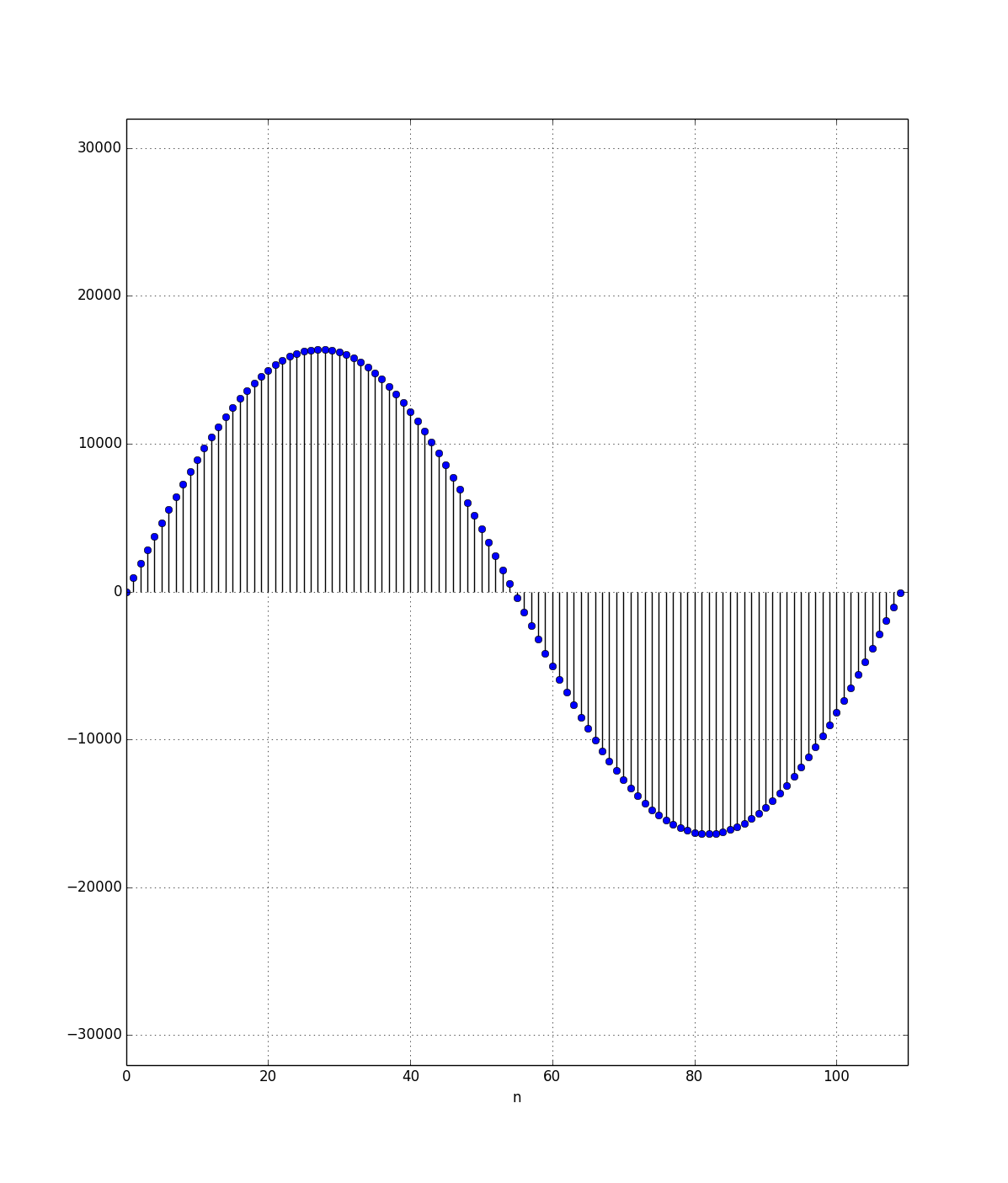 |
| ~100 samples of a 440Hz sine wave |

The smartwatch 2 is sony's new smartwatch. I got one from a hackerthon in Berlin, where everybody who attended got one from Sony. I liked to open it, but I'm a litte bit scared broking it's waterproofness. So I'll wait for ifixit or other disassembly website. Still I'm interested what's inside and how does it works?
The software side heavily depending on your android phone. There are some applications running direct on the watch. Like alarm clock, settings, countdown. Everything else is running on your phone and using it's display as canvas. Yes, you are writing over bluetooth into a canvas. When you are clicking on your watch, the Sony Smartwatch app on your phone is sending an broadcast intent which is starting your app. But that is a service in the background. For more information look into ligi's github repo.
Now get into the firmware and hardware. As Sony already written for the smartwatch (1) you can easy access the dfu bootloader. It's a dfu compatable bootloader. As already described on Sony's hacker documentation
dfu-util -l will show you when it's connected.
You can read and write it. Let's look into it.
dfu-util -l
Found DFU: [0fce:f0fa] devnum=0, cfg=1, intf=0, alt=0, name="@Internal Flash /0x08000000/03*016Kg,01*016Kg,01*064Kg,07*128Kg,03*016Kg,01*016Kg,01*064Kg,07*128Kg"
Found DFU: [0fce:f0fa] devnum=0, cfg=1, intf=0, alt=1, name="@eMMC /0x00000000/01*512Mg"
I think all firmware is placed within the first flash. It's the internal one. An eMMC is an soldered sdcard. Because we have the same partition layout twice, I think this is used for OTA firmware update. It's a common case on embedded device. Double size your flash and split it into 2 identical parts. I'll name the first part A and part B is the other half. We are booting part A, now an OTA update comes, the firmware will write this into part B and tell the bootloader: 'Try the B partition but only once.' Now the device will reboot and the bootloader boot part B. When the new firmware successful booted it tells the bootloader 'Boot everytime B now'. If the new firmware fails in B, the device has to be reboot and falling back to boot part A. This can be done by a hardware watchdog automatically.
I believe on the emmc we'll find all additional icons and application name we installed over the android. Remember the smartwatch is only a remote display with sensors. Nothing more.
Let's disassemble the firmware. Put your device into dfu mode. dfu has also upload capabilities. Upload means from device to a file. Download is for firmware flashing. Upload the 2M flash into a file.
dfu-util -a 0 -U /tmp/smartwatch_internal -s 0x08000000:2097152
Now let's do a simple strings /tmp/smartwatch_internal.
As we know from the settings menu we have an STM32F42x, a Cortex M4.
Look at the filenames.
Technical Details:
type: chip [interfaces] (detailed description)
CPU: STM32F4xx (STM32F-427 or 429)
RAM: 256k
ROM/flash: 2M
eMMC: 512M? [connected over sdio] (maybe less I could only load 128M over dfu-util. Could be also a edge in dfu-util)
BT: STLC2690 (low power but only BT 3.0. I guess low power means not BT4.0 low power. But it seems to has an own cortex m3 + fw upgrade functionality)
Accelerometer: bma250 [SPI (4-wire, 3-wire), i2c, 2 interrupt pins] (Bosch Sensoric)
Compass: ak8963 [SPI, I2C] (really? sony didn't exposed it or is this just a leftover from a debug board?)
NFC-tag: ntag203f [interupt pin for rf-activity] (only a tag - the mcu only knows if it got read)
Touch: ttsp3 (i'm not sure if this is a Cypress TTSP with i2c)
LiIonController: Max17048 [i2c] (fuel gauge and battery controller)
Light/AmbientSensor: Taos TSL2771 [I2C]
RTC: included CPU
Display: TC358763XBG [SPI (3,4 wire), SSI for display data; i2c, spi, pwm for control] (Display Controller)
Buzzer: GPIO wired
Most of the sensors and actors are already supported by linux kernel because they are built in some (Sony) smartphones. No I don't want run linux on it. But we have already working driver which we can adapt for an alternative firmware.
Search or github' search for STM32F4xx_StdPeriph_Driver which is freely available SDK. I think they don't written a complete firmware from scratch. Because of some strings I guess it's a 'uCos' extended to their needs.
Sony please provide us with the correct wiring of the sensors and actors so we can build our own firmware?!
Up until now, we’ve been using Android’s AudioFlinger for playing back and recording audio. Starting with tomorrow’s image, that is no longer true. Instead we’re talking directly from PulseAudio to ALSA, or the Android audio HAL when necessary.
In short, here’s how PulseAudio now works:
This provides somewhat of a compromise between features and porting effort: By using the ALSA library whenever we can, we can access PulseAudio’s timer scheduling and dynamic latency features. Having the straightest path possible for playing back music should help efficiency (and in extension, battery life). At least in theory – we haven’t actually done measurements.
Using the Audio HAL for everything mixer related would have been optimal, but it turns out that the audio HAL is too smart: it refuses to set up the mixer, unless PCM data is also sent to it, which is what we wanted to avoid. So then we had to set up the mixer manually too. However, we still could not avoid using the Audio HAL altogether: when starting and stopping voice calls, the Audio HAL talks to the modem and other components in the kernel to route the voice call between the modem and the sound card. Hence we ended up with this compromise approach.
Current status
At the time of this writing, this is working best on Nexus 4. The Galaxy Nexus works for the most part, except for bug 1217072. I intend to add Nexus 7 support shortly. If anyone wants to help testing Nexus 10, let me know.
For porters: if you need to do the same
Unfortunately, this means some additional work for porters, because you need to write UCM mixer files. What’s worse, UCM is lacking good documentation. For that reason, I hesitated somewhat before deciding to actually use UCM at all, but it’s the closest we have to a standard for setting up mixers on embedded devices right now.
But to give you a two-minute crash course in UCM and how it’s used in Ubuntu Touch – start by having a look in /usr/share/alsa/ucm/apq8064-tabla-snd-card/ directory. You’ll need to create a similar directory for your device. You’ll find the right directory name if you look in /proc/asound/cards.
Second, look at apq8064-tabla-snd-card.conf. Rename and copy into your own UCM directory. If you’re making a tablet image (that can’t make voice calls), you can remove the VoiceCall part (and the corresponding file).
Third, look at the HiFi file. This is where all fun happens. Notice the device names, which are hardcoded into telepathy-ofono and need to match: “Speaker”, “Earpiece” and “Headphone” for playback, plus “Handset” and “Headset” for recording.
Fourth, if you need voice calls, also look at the VoiceCall file. Btw, the verb names “HiFi” and “VoiceCall” also need to match.) This is largely empty, because the mixer setup is handled by the Audio HAL, but there is a twist here that took a while to get right: For PulseAudio’s UCM to work, it needs to open a PCM device. However, at the time where UCM tests this, the voice call is not yet set up. So, you might need to set up the mixer just a little, so that the PCM can open. (On desktops, PCM can always open, regardless of mixer state. This is not always true on embedded devices, that are using ASoC.) It’s a bonus if you can find a PCM that actually plays back audio, because then you can get notification sounds while on the phone.
And this concludes the two minute crash course – happy porting!
(Side note: Sorry if the permalink – or comment pages etc – to this blog leads you to a blank page. I’ve reported the bug to the relevant team in Canonical, but at the time of this posting, they are looking into it but have not yet fixed it.)
 |
| 440Hz sine wave sampled at 48kHz |
 |
| 440Hz sine wave resampled to 96kHz |
 |
| Performance using signed 16-bit integers as the sample format |
 |
| Performance using floating point numbers as the sample format |
This is a public service announcement for packagers and users of Skype and PulseAudio 4.0.
In PulseAudio 4.0, we added some code to allow us to deal with automatic latency adjustment more gracefully, particularly for latency requests under ~80 ms. This exposed a bug in Skype that breaks audio in interesting ways (no sound, choppy sound, playback happens faster than it should).
We’ve spoken to the Skype developers about this problem and they have been investigating the problem. In the mean time, we suggest that users and packagers work around this problem in the mean time.
If you are packaging Skype for your distribution, you need to change the Exec line in your Skype .desktop file as follows:
Exec=env PULSE_LATENCY_MSEC=60 skype %U
If you are a user, and your distribution doesn’t already carry this fix (as of about a week ago, Ubuntu does, and as of ~1 hour from now, Gentoo will), you need to launch Skype from the command line as follows:
$ PULSE_LATENCY_MSEC=60 skype
If you’re not sure if you’re hit but this bug, you’re probably not. :-)
After reading some documentation and a lot of code. A somehow working module evolves. It supports simple module argument, it can connect to a remote server and also plays audio.
But the problems starting here, because threads are nice and can hurt you because of context. For the first version it is good to hear voices in my ears coming out of speakers over a network. I implemented an early version with a lot of downsides:
What I've done wrong was attaching libpulse on pulse server mainloop. Every context and stream callback was run by the mainloop as well as read operations. Not good thing. Only pa_sink_render is working within the I/O thread. Zero copy for now is broken by libpulse, because using pa_stream_write without a free_callback will copy the samples into an internal buffer.
But for the first version ok. Fixing my threading problem is easy move everything inside our thread. What means create a mainloop for the libpulse. My first thought, that could not be hard, because epoll, a modern efficient select replacement supports chaining. Just chain or combine rt_poll with our libpulse mainloop. Not a easy solution. Combining a mainloop poll and a rt poll is hard, because of two lists of filedescriptors which can not be simple appended. Both lists get generated each time poll runs.
Stepping a step back and asking why should I use rt_poll? Is there another solution which fits much more the concept of using a second mainloop?
A thread only working as a mainloop should also work. The only task what the thread must take case is the pa_thread_mq.
On my journey to a new module-tunnel I took a closer look into other modules. Pulseaudio got modules for event handling, got modules for os driver frameworks like alsa, oss, solaris. Also there a drivers to communicate over the local network. Starting with mod-native-protocol-tcp to allow remote pulseaudio connections, there is also support for esound, zeroconf, rtp or raop. Modify sound stream samples is also possible, take a look into the filters.
To write a hardware driver or network based driver I would recommend reading null-sink, raop-sink and esound-sink.
After looking around into several pulse modules. It is clear that most of the module which act as a sink have the following structure and nearby the same code beside from driver specific parts. :::c void thread_func() { / hard work / }
int pa__init(pa_module*m) {
/* parse + validate + copy module arguments */
pa_modargs_new(m->argument, valid_modargs)
/* init driver specific */
/* setup a real time poll */
u->rtpoll = pa_rtpoll_new();
/* setup a message queue */
pa_thread_mq_init(&u->thread_mq, m->core->mainloop, u->rtpoll
pa_sink_set_asyncmsgq(u->sink, u->thread_mq.inq);
/* create a thread */
pa_thread_new("null-sink", thread_func, u)
/* register sink */
pa_sink_put(u->sink);
}
int pa__done(pa_module*m) {
/* deinit private structure + free everything */
}
All sink modules have a real time poll running in a seperated thread, often also caled I/O thread. This is because of [http://www.freedesktop.org/wiki/Software/PulseAudio/Documentation/Developer/Threading/|the threading model]. In summary it says "don't block the mainloop and do the hard work within the I/O loop."
Back to our thread, is has to do the real work of our module. It's dequeuing data from
a sink buffer, mixing and adjusting volumes. This set of tasks is named rendering. It is done by pa_sink_render.
Syncronisation is done by message queues between mainloop and I/O loop named pa_thread_mq which has 2 pa_asyncmsgq one input queue for message to the thread and one output queue from thread to the mainloop.
rtpoll is not as powerfull a mainloop is, but you can register at least a filehandler packed within rt_poll_item. When you write a network protocol this will be your socket.
After one month here comes my first blog post about it. My gsoc project is creating a new mod-tunnel using libpulse api.
You can use module-tunnel to connect your local pulseaudio to a remote pulseaudio. This is quite usefull, because you can stream over the network your audio from laptop to a dedicated sound system with real speakers. With pavucontrol you can move simple move a stream from local output device to the remote one. In combination with mod-zeroconf-discover and mod-zeroconf-publish it will automatic find other pulseaudio servers and connects to them.
What module-tunnel really does is creating a virtual sound card on your local pulseaudio server. On the remote site it creates a client as every other normal sound application like mplayer, vlc, [...]
Why I'm rewriting a complete module?' Before saying anything about it, mod-tunnel seems to be a very old module from the beginning. But it has a lot of downside beside the good one that it works as long you have a stable connection to the remote server.
Hi. Time for a quick update about my Summer of Code project.
I'm going to talk a little about my first checklist item, refactoring the resampling code. While refactoring isn't quite exciting as implementing new features it is a necessity to assure code maintainability.
So let's take a look at the resampler interface and see what we can do. The interface consists of a pa_resampler structure which we create if we want to do some resampling. This structure holds all of our settings the resampler cares about, (sample specifications, different buffers) but also some specific data for different resampling implementations.
The interesting bits are shown bellow.
After the implementation specific function pointers we can see multiple structures holding implementation specific data. Since the resampler can't switch implementations on the fly (without destroying and recreating a resampler) only one of these structures is used at a time.
struct pa_resampler {
...
void (*impl_free)(pa_resampler *r);
void (*impl_update_rates)(pa_resampler *r);
void (*impl_resample)(pa_resampler *r, const pa_memchunk *in,
unsigned in_samples, pa_memchunk *out,
unsigned *out_samples);
void (*impl_reset)(pa_resampler *r);
struct { /* data specific to the trivial resampler */
unsigned o_counter;
unsigned i_counter;
} trivial;
struct { /* data specific to the peak finder pseudo resampler */
unsigned o_counter;
unsigned i_counter;
float max_f[PA_CHANNELS_MAX];
int16_t max_i[PA_CHANNELS_MAX];
} peaks;
...
};
Further bellow of the file we see a big init_table containing the mapping between a resampling method (an enumeration) and its initialization function.
As we can see there are quite some duplicates here. There are a total of 32 entries while only having 6 distinctive init functions. There is another big table like this containing the implementation names, this table doesn't contain any duplicates but it would be nice if we could group the implementation names into smaller implementation specific tables. So without further ado here is the first code snippet with the appropriate changes.
static int (* const init_table[])(pa_resampler*r) = {
[PA_RESAMPLER_SRC_SINC_BEST_QUALITY] = libsamplerate_init,
[PA_RESAMPLER_SRC_SINC_MEDIUM_QUALITY] = libsamplerate_init,
[PA_RESAMPLER_SRC_SINC_FASTEST] = libsamplerate_init,
[PA_RESAMPLER_SRC_ZERO_ORDER_HOLD] = libsamplerate_init,
[PA_RESAMPLER_SRC_LINEAR] = libsamplerate_init,
[PA_RESAMPLER_TRIVIAL] = trivial_init,
[PA_RESAMPLER_SPEEX_FLOAT_BASE+0] = speex_init,
[PA_RESAMPLER_SPEEX_FLOAT_BASE+1] = speex_init,
...
[PA_RESAMPLER_SPEEX_FLOAT_BASE+10] = speex_init,
[PA_RESAMPLER_SPEEX_FIXED_BASE+0] = speex_init,
...
[PA_RESAMPLER_SPEEX_FIXED_BASE+10] = speex_init,
...
All the implementation specific data is now contained inside a single structure.
struct pa_resampler {
...
pa_resampler_implementation implementation;
...
};
No more duplicate entries here.
static pa_resampler_implementation *impl_table[] = {
[PA_RESAMPLER_SRC_SINC_FASTEST] = &libsamplerate_impl,
[PA_RESAMPLER_TRIVIAL] = &trivial_impl,
[PA_RESAMPLER_SPEEX_FLOAT_BASE] = &speex_impl,
[PA_RESAMPLER_FFMPEG] = &ffmpeg_impl,
[PA_RESAMPLER_AUTO] = &auto_impl,
[PA_RESAMPLER_COPY] = ©_impl,
[PA_RESAMPLER_PEAKS] = &peaks_impl,
};
The implementation specific structures are replaced by a simple opaque data entry and the implementations init function takes care of the allocating. The big names table is also now split up and contained inside this structure.
struct pa_resampler_implementation {
int (*init)(pa_resampler *r);
void (*free)(pa_resampler *r);
void (*update_rates)(pa_resampler *r);
void (*resample)(pa_resampler *r, const pa_memchunk *in,
unsigned in_samples, pa_memchunk *out,
unsigned *out_samples);
void (*reset)(pa_resampler *r);
void *data;
const char *names[PA_RESAMPLER_MAX_VARIANTS];
};
These changes aren't yet merged upstream and some of it may change if needed. Further details are on my github page.
Thats it for now, next time there should be a more interesting topic. Thanks for your attention and bye.
And we’re back … PulseAudio 4.0 is out! There’s both a short and super-detailed changelog in the release notes. For the lazy, this release brings a bunch of Bluetooth stability updates, better low latency handling, performance improvements, and a whole lot more. :)
One interesting thing is that for this release, we kept a parallel next branch open while master was frozen for stabilising and releasing. As a result, we’re already well on our way to 5.0 with 52 commits since 4.0 already merged into master.
And finally, I’m excited to announce PulseAudio is going to be carrying out two great projects this summer, as part of the Google Summer of Code! We are going to have Alexander Couzens (lynxis) working on a rewrite of module-tunnel using libpulse, mentored by Tanu Kaskinen. In addition to this, Damir Jelić (poljar) working on improvements to resampling, mentored by Peter Meerwald.
That’s just some of the things to look forward to in coming months. I’ve got a few more things I’d like to write about, but I’ll save that for another post.
That’s right — PulseAudio will be participating in the Google Summer of Code again this year! We had a great set of students and projects last year, and you’ve already seen some their work in the last release.
There are some more details on how to get involved on the mailing list. We’re looking forward to having another set of smart and enthusiastic new contributors this year!
p.s.: Mentors and students from organisations (GStreamer and BlueZ, for example), do feel free to get in touch with us if you have ideas for projects related to PulseAudio that overlap with those other projects.
Since we first proposed systemd for inclusion in the distributions it has been frequently discussed in many forums, mailing lists and conferences. In these discussions one can often hear certain myths about systemd, that are repeated over and over again, but certainly don't gain any truth by constant repetition. Let's take the time to debunk a few of them:
Myth: systemd is monolithic.
If you build systemd with all configuration options enabled you will build 69 individual binaries. These binaries all serve different tasks, and are neatly separated for a number of reasons. For example, we designed systemd with security in mind, hence most daemons run at minimal privileges (using kernel capabilities, for example) and are responsible for very specific tasks only, to minimize their security surface and impact. Also, systemd parallelizes the boot more than any prior solution. This parallization happens by running more processes in parallel. Thus it is essential that systemd is nicely split up into many binaries and thus processes. In fact, many of these binaries[1] are separated out so nicely, that they are very useful outside of systemd, too.
A package involving 69 individual binaries can hardly be called monolithic. What is different from prior solutions however, is that we ship more components in a single tarball, and maintain them upstream in a single repository with a unified release cycle.
Myth: systemd is about speed.
Yes, systemd is fast (A pretty complete userspace boot-up in ~900ms, anyone?), but that's primarily just a side-effect of doing things right. In fact, we never really sat down and optimized the last tiny bit of performance out of systemd. Instead, we actually frequently knowingly picked the slightly slower code paths in order to keep the code more readable. This doesn't mean being fast was irrelevant for us, but reducing systemd to its speed is certainly quite a misconception, since that is certainly not anywhere near the top of our list of goals.
Myth: systemd's fast boot-up is irrelevant for servers.
That is just completely not true. Many administrators actually are keen on reduced downtimes during maintenance windows. In High Availability setups it's kinda nice if the failed machine comes back up really fast. In cloud setups with a large number of VMs or containers the price of slow boots multiplies with the number of instances. Spending minutes of CPU and IO on really slow boots of hundreds of VMs or containers reduces your system's density drastically, heck, it even costs you more energy. Slow boots can be quite financially expensive. Then, fast booting of containers allows you to implement a logic such as socket activated containers, allowing you to drastically increase the density of your cloud system.
Of course, in many server setups boot-up is indeed irrelevant, but systemd is supposed to cover the whole range. And yes, I am aware that often it is the server firmware that costs the most time at boot-up, and the OS anyways fast compared to that, but well, systemd is still supposed to cover the whole range (see above...), and no, not all servers have such bad firmware, and certainly not VMs and containers, which are servers of a kind, too.[2]
Myth: systemd is incompatible with shell scripts.
This is entirely bogus. We just don't use them for the boot process, because we believe they aren't the best tool for that specific purpose, but that doesn't mean systemd was incompatible with them. You can easily run shell scripts as systemd services, heck, you can run scripts written in any language as systemd services, systemd doesn't care the slightest bit what's inside your executable. Moreover, we heavily use shell scripts for our own purposes, for installing, building, testing systemd. And you can stick your scripts in the early boot process, use them for normal services, you can run them at latest shutdown, there are practically no limits.
Myth: systemd is difficult.
This also is entire non-sense. A systemd platform is actually much simpler than traditional Linuxes because it unifies system objects and their dependencies as systemd units. The configuration file language is very simple, and redundant configuration files we got rid of. We provide uniform tools for much of the configuration of the system. The system is much less conglomerate than traditional Linuxes are. We also have pretty comprehensive documentation (all linked from the homepage) about pretty much every detail of systemd, and this not only covers admin/user-facing interfaces, but also developer APIs.
systemd certainly comes with a learning curve. Everything does. However, we like to believe that it is actually simpler to understand systemd than a Shell-based boot for most people. Surprised we say that? Well, as it turns out, Shell is not a pretty language to learn, it's syntax is arcane and complex. systemd unit files are substantially easier to understand, they do not expose a programming language, but are simple and declarative by nature. That all said, if you are experienced in shell, then yes, adopting systemd will take a bit of learning.
To make learning easy we tried hard to provide the maximum compatibility to previous solutions. But not only that, on many distributions you'll find that some of the traditional tools will now even tell you -- while executing what you are asking for -- how you could do it with the newer tools instead, in a possibly nicer way.
Anyway, the take-away is probably that systemd is probably as simple as such a system can be, and that we try hard to make it easy to learn. But yes, if you know sysvinit then adopting systemd will require a bit learning, but quite frankly if you mastered sysvinit, then systemd should be easy for you.
Myth: systemd is not modular.
Not true at all. At compile time you have a number of configure switches to select what you want to build, and what not. And we document how you can select in even more detail what you need, going beyond our configure switches.
This modularity is not totally unlike the one of the Linux kernel, where you can select many features individually at compile time. If the kernel is modular enough for you then systemd should be pretty close, too.
Myth: systemd is only for desktops.
That is certainly not true. With systemd we try to cover pretty much the same range as Linux itself does. While we care for desktop uses, we also care pretty much the same way for server uses, and embedded uses as well. You can bet that Red Hat wouldn't make it a core piece of RHEL7 if it wasn't the best option for managing services on servers.
People from numerous companies work on systemd. Car manufactureres build it into cars, Red Hat uses it for a server operating system, and GNOME uses many of its interfaces for improving the desktop. You find it in toys, in space telescopes, and in wind turbines.
Most features I most recently worked on are probably relevant primarily on servers, such as container support, resource management or the security features. We cover desktop systems pretty well already, and there are number of companies doing systemd development for embedded, some even offer consulting services in it.
Myth: systemd was created as result of the NIH syndrome.
This is not true. Before we began working on systemd we were pushing for Canonical's Upstart to be widely adopted (and Fedora/RHEL used it too for a while). However, we eventually came to the conclusion that its design was inherently flawed at its core (at least in our eyes: most fundamentally, it leaves dependency management to the admin/developer, instead of solving this hard problem in code), and if something's wrong in the core you better replace it, rather than fix it. This was hardly the only reason though, other things that came into play, such as the licensing/contribution agreement mess around it. NIH wasn't one of the reasons, though...[3]
Myth: systemd is a freedesktop.org project.
Well, systemd is certainly hosted at fdo, but freedesktop.org is little else but a repository for code and documentation. Pretty much any coder can request a repository there and dump his stuff there (as long as it's somewhat relevant for the infrastructure of free systems). There's no cabal involved, no "standardization" scheme, no project vetting, nothing. It's just a nice, free, reliable place to have your repository. In that regard it's a bit like SourceForge, github, kernel.org, just not commercial and without over-the-top requirements, and hence a good place to keep our stuff.
So yes, we host our stuff at fdo, but the implied assumption of this myth in that there was a group of people who meet and then agree on how the future free systems look like, is entirely bogus.
Myth: systemd is not UNIX.
There's certainly some truth in that. systemd's sources do not contain a single line of code originating from original UNIX. However, we derive inspiration from UNIX, and thus there's a ton of UNIX in systemd. For example, the UNIX idea of "everything is a file" finds reflection in that in systemd all services are exposed at runtime in a kernel file system, the cgroupfs. Then, one of the original features of UNIX was multi-seat support, based on built-in terminal support. Text terminals are hardly the state of the art how you interface with your computer these days however. With systemd we brought native multi-seat support back, but this time with full support for today's hardware, covering graphics, mice, audio, webcams and more, and all that fully automatic, hotplug-capable and without configuration. In fact the design of systemd as a suite of integrated tools that each have their individual purposes but when used together are more than just the sum of the parts, that's pretty much at the core of UNIX philosophy. Then, the way our project is handled (i.e. maintaining much of the core OS in a single git repository) is much closer to the BSD model (which is a true UNIX, unlike Linux) of doing things (where most of the core OS is kept in a single CVS/SVN repository) than things on Linux ever were.
Ultimately, UNIX is something different for everybody. For us systemd maintainers it is something we derive inspiration from. For others it is a religion, and much like the other world religions there are different readings and understandings of it. Some define UNIX based on specific pieces of code heritage, others see it just as a set of ideas, others as a set of commands or APIs, and even others as a definition of behaviours. Of course, it is impossible to ever make all these people happy.
Ultimately the question whether something is UNIX or not matters very little. Being technically excellent is hardly exclusive to UNIX. For us, UNIX is a major influence (heck, the biggest one), but we also have other influences. Hence in some areas systemd will be very UNIXy, and in others a little bit less.
Myth: systemd is complex.
There's certainly some truth in that. Modern computers are complex beasts, and the OS running on it will hence have to be complex too. However, systemd is certainly not more complex than prior implementations of the same components. Much rather, it's simpler, and has less redundancy (see above). Moreover, building a simple OS based on systemd will involve much fewer packages than a traditional Linux did. Fewer packages makes it easier to build your system, gets rid of interdependencies and of much of the different behaviour of every component involved.
Myth: systemd is bloated.
Well, bloated certainly has many different definitions. But in most definitions systemd is probably the opposite of bloat. Since systemd components share a common code base, they tend to share much more code for common code paths. Here's an example: in a traditional Linux setup, sysvinit, start-stop-daemon, inetd, cron, dbus, all implemented a scheme to execute processes with various configuration options in a certain, hopefully clean environment. On systemd the code paths for all of this, for the configuration parsing, as well as the actual execution is shared. This means less code, less place for mistakes, less memory and cache pressure, and is thus a very good thing. And as a side-effect you actually get a ton more functionality for it...
As mentioned above, systemd is also pretty modular. You can choose at build time which components you need, and which you don't need. People can hence specifically choose the level of "bloat" they want.
When you build systemd, it only requires three dependencies: glibc, libcap and dbus. That's it. It can make use of more dependencies, but these are entirely optional.
So, yeah, whichever way you look at it, it's really not bloated.
Myth: systemd being Linux-only is not nice to the BSDs.
Completely wrong. The BSD folks are pretty much uninterested in systemd. If systemd was portable, this would change nothing, they still wouldn't adopt it. And the same is true for the other Unixes in the world. Solaris has SMF, BSD has their own "rc" system, and they always maintained it separately from Linux. The init system is very close to the core of the entire OS. And these other operating systems hence define themselves among other things by their core userspace. The assumption that they'd adopt our core userspace if we just made it portable, is completely without any foundation.
Myth: systemd being Linux-only makes it impossible for Debian to adopt it as default.
Debian supports non-Linux kernels in their distribution. systemd won't run on those. Is that a problem though, and should that hinder them to adopt system as default? Not really. The folks who ported Debian to these other kernels were willing to invest time in a massive porting effort, they set up test and build systems, and patched and built numerous packages for their goal. The maintainance of both a systemd unit file and a classic init script for the packaged services is a negligable amount of work compared to that, especially since those scripts more often than not exist already.
Myth: systemd could be ported to other kernels if its maintainers just wanted to.
That is simply not true. Porting systemd to other kernel is not feasible. We just use too many Linux-specific interfaces. For a few one might find replacements on other kernels, some features one might want to turn off, but for most this is nor really possible. Here's a small, very incomprehensive list: cgroups, fanotify, umount2(), /proc/self/mountinfo (including notification), /dev/swaps (same), udev, netlink, the structure of /sys, /proc/$PID/comm, /proc/$PID/cmdline, /proc/$PID/loginuid, /proc/$PID/stat, /proc/$PID/session, /proc/$PID/exe, /proc/$PID/fd, tmpfs, devtmpfs, capabilities, namespaces of all kinds, various prctl()s, numerous ioctls, the mount() system call and its semantics, selinux, audit, inotify, statfs, O_DIRECTORY, O_NOATIME, /proc/$PID/root, waitid(), SCM_CREDENTIALS, SCM_RIGHTS, mkostemp(), /dev/input, ...
And no, if you look at this list and pick out the few where you can think of obvious counterparts on other kernels, then think again, and look at the others you didn't pick, and the complexity of replacing them.
Myth: systemd is not portable for no reason.
Non-sense! We use the Linux-specific functionality because we need it to implement what we want. Linux has so many features that UNIX/POSIX didn't have, and we want to empower the user with them. These features are incredibly useful, but only if they are actually exposed in a friendly way to the user, and that's what we do with systemd.
Myth: systemd uses binary configuration files.
No idea who came up with this crazy myth, but it's absolutely not true. systemd is configured pretty much exclusively via simple text files. A few settings you can also alter with the kernel command line and via environment variables. There's nothing binary in its configuration (not even XML). Just plain, simple, easy-to-read text files.
Myth: systemd is a feature creep.
Well, systemd certainly covers more ground that it used to. It's not just an init system anymore, but the basic userspace building block to build an OS from, but we carefully make sure to keep most of the features optional. You can turn a lot off at compile time, and even more at runtime. Thus you can choose freely how much feature creeping you want.
Myth: systemd forces you to do something.
systemd is not the mafia. It's Free Software, you can do with it whatever you want, and that includes not using it. That's pretty much the opposite of "forcing".
Myth: systemd makes it impossible to run syslog.
Not true, we carefully made sure when we introduced the journal that all data is also passed on to any syslog daemon running. In fact, if something changed, then only that syslog gets more complete data now than it got before, since we now cover early boot stuff as well as STDOUT/STDERR of any system service.
Myth: systemd is incompatible.
We try very hard to provide the best possible compatibility with sysvinit. In fact, the vast majority of init scripts should work just fine on systemd, unmodified. However, there actually are indeed a few incompatibilities, but we try to document these and explain what to do about them. Ultimately every system that is not actually sysvinit itself will have a certain amount of incompatibilities with it since it will not share the exect same code paths.
It is our goal to ensure that differences between the various distributions are kept at a minimum. That means unit files usually work just fine on a different distribution than you wrote it on, which is a big improvement over classic init scripts which are very hard to write in a way that they run on multiple Linux distributions, due to numerous incompatibilities between them.
Myth: systemd is not scriptable, because of its D-Bus use.
Not true. Pretty much every single D-Bus interface systemd provides is also available in a command line tool, for example in systemctl, loginctl, timedatectl, hostnamectl, localectl and suchlike. You can easily call these tools from shell scripts, they open up pretty much the entire API from the command line with easy-to-use commands.
That said, D-Bus actually has bindings for almost any scripting language this world knows. Even from the shell you can invoke arbitrary D-Bus methods with dbus-send or gdbus. If anything, this improves scriptability due to the good support of D-Bus in the various scripting languages.
Myth: systemd requires you to use some arcane configuration tools instead of allowing you to edit your configuration files directly.
Not true at all. We offer some configuration tools, and using them gets you a bit of additional functionality (for example, command line completion for all settings!), but there's no need at all to use them. You can always edit the files in question directly if you wish, and that's fully supported. Of course sometimes you need to explicitly reload configuration of some daemon after editing the configuration, but that's pretty much true for most UNIX services.
Myth: systemd is unstable and buggy.
Certainly not according to our data. We have been monitoring the Fedora bug tracker (and some others) closely for a long long time. The number of bugs is very low for such a central component of the OS, especially if you discount the numerous RFE bugs we track for the project. We are pretty good in keeping systemd out of the list of blocker bugs of the distribution. We have a relatively fast development cycle with mostly incremental changes to keep quality and stability high.
Myth: systemd is not debuggable.
False. Some people try to imply that the shell was a good debugger. Well, it isn't really. In systemd we provide you with actual debugging features instead. For example: interactive debugging, verbose tracing, the ability to mask any component during boot, and more. Also, we provide documentation for it.
It's certainly well debuggable, we needed that for our own development work, after all. But we'll grant you one thing: it uses different debugging tools, we believe more appropriate ones for the purpose, though.
Myth: systemd makes changes for the changes' sake.
Very much untrue. We pretty much exclusively have technical reasons for the changes we make, and we explain them in the various pieces of documentation, wiki pages, blog articles, mailing list announcements. We try hard to avoid making incompatible changes, and if we do we try to document the why and how in detail. And if you wonder about something, just ask us!
Myth: systemd is a Red-Hat-only project, is private property of some smart-ass developers, who use it to push their views to the world.
Not true. Currently, there are 16 hackers with commit powers to the systemd git tree. Of these 16 only six are employed by Red Hat. The 10 others are folks from ArchLinux, from Debian, from Intel, even from Canonical, Mandriva, Pantheon and a number of community folks with full commit rights. And they frequently commit big stuff, major changes. Then, there are 374 individuals with patches in our tree, and they too came from a number of different companies and backgrounds, and many of those have way more than one patch in the tree. The discussions about where we want to take systemd are done in the open, on our IRC channel (#systemd on freenode, you are always weclome), on our mailing list, and on public hackfests (such as our next one in Brno, you are invited). We regularly attend various conferences, to collect feedback, to explain what we are doing and why, like few others do. We maintain blogs, engage in social networks (we actually have some pretty interesting content on Google+, and our Google+ Community is pretty alive, too.), and try really hard to explain the why and the how how we do things, and to listen to feedback and figure out where the current issues are (for example, from that feedback we compiled this lists of often heard myths about systemd...).
What most systemd contributors probably share is a rough idea how a good OS should look like, and the desire to make it happen. However, by the very nature of the project being Open Source, and rooted in the community systemd is just what people want it to be, and if it's not what they want then they can drive the direction with patches and code, and if that's not feasible, then there are numerous other options to use, too, systemd is never exclusive.
One goal of systemd is to unify the dispersed Linux landscape a bit. We try to get rid of many of the more pointless differences of the various distributions in various areas of the core OS. As part of that we sometimes adopt schemes that were previously used by only one of the distributions and push it to a level where it's the default of systemd, trying to gently push everybody towards the same set of basic configuration. This is never exclusive though, distributions can continue to deviate from that if they wish, however, if they end-up using the well-supported default their work becomes much easier and they might gain a feature or two. Now, as it turns out, more frequently than not we actually adopted schemes that where Debianisms, rather than Fedoraisms/Redhatisms as best supported scheme by systemd. For example, systems running systemd now generally store their hostname in /etc/hostname, something that used to be specific to Debian and now is used across distributions.
One thing we'll grant you though, we sometimes can be smart-asses. We try to be prepared whenever we open our mouth, in order to be able to back-up with facts what we claim. That might make us appear as smart-asses.
But in general, yes, some of the more influental contributors of systemd work for Red Hat, but they are in the minority, and systemd is a healthy, open community with different interests, different backgrounds, just unified by a few rough ideas where the trip should go, a community where code and its design counts, and certainly not company affiliation.
Myth: systemd doesn't support /usr split from the root directory.
Non-sense. Since its beginnings systemd supports the --with-rootprefix= option to its configure script which allows you to tell systemd to neatly split up the stuff needed for early boot and the stuff needed for later on. All this logic is fully present and we keep it up-to-date right there in systemd's build system.
Of course, we still don't think that actually booting with /usr unavailable is a good idea, but we support this just fine in our build system. This won't fix the inherent problems of the scheme that you'll encounter all across the board, but you can't blame that on systemd, because in systemd we support this just fine.
Myth: systemd doesn't allow your to replace its components.
Not true, you can turn off and replace pretty much any part of systemd, with very few exceptions. And those exceptions (such as journald) generally allow you to run an alternative side by side to it, while cooperating nicely with it.
Myth: systemd's use of D-Bus instead of sockets makes it intransparent.
This claim is already contradictory in itself: D-Bus uses sockets as transport, too. Hence whenever D-Bus is used to send something around, a socket is used for that too. D-Bus is mostly a standardized serialization of messages to send over these sockets. If anything this makes it more transparent, since this serialization is well documented, understood and there are numerous tracing tools and language bindings for it. This is very much unlike the usual homegrown protocols the various classic UNIX daemons use to communicate locally.
Hmm, did I write I just wanted to debunk a "few" myths? Maybe these were more than just a few... Anyway, I hope I managed to clear up a couple of misconceptions. Thanks for your time.
Footnotes
[1] For example, systemd-detect-virt, systemd-tmpfiles, systemd-udevd are.
[2] Also, we are trying to do our little part on maybe making this better. By exposing boot-time performance of the firmware more prominently in systemd's boot output we hope to shame the firmware writers to clean up their stuff.
[3] And anyways, guess which project includes a library "libnih" -- Upstart or systemd?[4]
[4] Hint: it's not systemd!
Yay, we just released PulseAudio 3.0! I’m not going to rehash the changelog that you can find in the release announcement as well as the longer release notes.
I would like to thank the 36 contributors over the last 6 months who have made this release what it is and continue to demonstrate what a vibrant community we have!
For those of you who missed my previous updates, we recently organised a PulseAudio miniconference in Copenhagen, Denmark last week. The organisation of all this was spearheaded by ALSA and PulseAudio hacker, David Henningsson. The good folks organising the Ubuntu Developer Summit / Linaro Connect were kind enough to allow us to colocate this event. A big thanks to both of them for making this possible!
 The room where the first PulseAudio conference took place
The room where the first PulseAudio conference took place
The conference was attended by the four current active PulseAudio developers: Colin Guthrie, Tanu Kaskinen, David Henningsson, and myself. We were joined by long-time contributors Janos Kovacs and Jaska Uimonen from Intel, Luke Yelavich, Conor Curran and Michał Sawicz.
We started the conference at around 9:30 am on November 2nd, and actually managed to keep to the final schedule(!), so I’m going to break this report down into sub-topics for each item which will hopefully make for easier reading than an essay. I’ve also put up some photos from the conference on the Google+ event.
We started off with a broad topic — what each of our personal visions/goals for the project are. Interestingly, two main themes emerged: having the most seamless desktop user experience possible, and making sure we are well-suited to the embedded world.
Most of us expressed interest in making sure that users of various desktops had a smooth, hassle-free audio experience. In the ideal case, they would never need to find out what PulseAudio is!
Orthogonally, a number of us are also very interested in making PulseAudio a strong contender in the embedded space (mobile phones, tablets, set top boxes, cars, and so forth). While we already find PulseAudio being used in some of these, there are areas where we can do better (more in later topics).
There was some reservation expressed about other, less-used features such as network playback being ignored because of this focus. The conclusion after some discussion was that this would not be the case, as a number of embedded use-cases do make use of these and other “fringe” features.
Contributors to PulseAudio will be aware that our patch queue has been growing for the last few months due to lack of developer time. We discussed several ways to deal with this problem, the most promising of which was a periodic triage meeting.
We will be setting up a rotating schedule where each of us will organise a meeting every 2 weeks (the period might change as we implement things) where we can go over outstanding patches and hopefully clear backlog. Colin has agreed to set up the first of these.
Next on the agenda was a presentation by Janos Kovacs about the work they’ve been doing at Intel with enhancing the PulseAudio’s routing infrastructure. These are being built from the perspective of IVI systems (i.e., cars) which typically have fairly complex use cases involving multiple concurrent devices and users. The slides for the talk will be put up here shortly (edit: slides are now available).
The talk was mingled with a Q&A type discussion with Janos and Jaska. The first item of discussion was consolidating Colin’s priority-based routing ideas into the proposed infrastructure. The broad thinking was that the ideas were broadly compatible and should be implementable in the new model.
There was also some discussion on merging the module-combine-sink functionality into PulseAudio’s core, in order to make 1:N routing easier. Some alternatives using te module-filter-* were proposed. Further discussion will likely be required before this is resolved.
The next steps for this work are for Jaska and Janos to break up the code into smaller logical bits so that we can start to review the concepts and code in detail and work towards eventually merging as much as makes sense upstream.
This session was taken up against the background of improving latency for games on the desktop (although it does have other applications). The indicated required latency for games was given as 16 ms (corresponding to a frame rate of 60 fps). A number of ideas to deal with the problem were brought up.
Firstly, it was suggested that the maxlength buffer attribute when setting up streams could be used to signal a hard limit on stream latency — the client signals that it will prefer an underrun, over a latency above maxlength.
Another long-standing item was to investigate the cause of underruns as we lower latency on the stream — David has already begun taking this up on the LKML.
Finally, another long-standing issue is the buffer attribute adjustment done during stream setup. This is not very well-suited to low-latency applications. David and I will be looking at this in coming days.
Tanu led the topic of finding a way to deal with use-cases such as mpd or multi-user systems, where access to the PulseAudio daemon of the active user by another user might be desired. Multiple suggestions were put forward, though a definite conclusion was not reached, as further thought is required.
Tanu’s suggestion was a split between a per-user daemon to manage tasks such as per-user configuration, and a system-wide daemon to manage the actual audio resources. The rationale being that the hardware itself is a common resource and could be handled by a non-user-specific daemon instance. This approach has the advantage of having a single entity in charge of the hardware, which keeps a part of the implementation simpler. The disadvantage is that we will either sacrifice security (arbitrary users can “eavesdrop” using the machine’s mic), or security infrastructure will need to be added to decide what users are allowed what access.
I suggested that since these are broadly fringe use-cases, we should document how users can configure the system by hand for these purposes, the crux of the argument being that our architecture should be dictated by the main use-cases, and not the ancillary ones. The disadvantage of this approach is, of course, that configuration is harder for the minority that wishes multi-user access to the hardware.
Colin suggested a mechanism for users to be able to request access from an “active” PulseAudio daemon, which could trigger approval by the corresponding “active” user. The communication mechanism could be the D-Bus system bus between user daemons, and Ștefan Săftescu’s Google Summer of Code work to allow desktop notifications to be triggered from PulseAudio could be used to get to request authorisation.
David suggested that we could use the per-user/system-wide split, modified somewhat to introduce the concept of a “system-wide” card. This would be a device that is configured as being available to the whole system, and thus explicitly marked as not having any privacy guarantees.
In both the above cases, discussion continued about deciding how the access control would be handled, and this remains open.
We will be continuing to look at this problem until consensus emerges.
The next topic dealt with being able to deal with laptops with a built-in 2.1 channel set up. The background of this is that there are a number of laptops with stereo speakers and a subwoofer. These are usually used as stereo devices with the subwoofer implicitly being fed data by the audio controller in some hardware-dependent way.
The possibility of exposing this hardware more accurately was discussed. Some investigation is required to see how things are currently exposed for various hardware (my MacBook Pro exposes the subwoofer as a surround control, for example). We need to deal with correctly exposing the hardware at the ALSA layer, and then using that correctly in PulseAudio profiles.
This led to a discussion of how we could handle profiles for these. Ideally, we would have a stereo profile with the hardware dealing with upmixing, and a 2.1 profile that would be automatically triggered when a stream with an LFE channel was presented. This is a general problem while dealing with surround output on HDMI as well, and needs further thought as it complicates routing.
I gave a rousing speech about writing more tests using some of the new improvements to our testing framework. Much cheering and acknowledgement ensued.
Ed.: some literary liberties might have been taken in this section
I missed a large part of this unfortunately, but the crux if the discussion was around unifying cross-distribution sound configuration for those who wish to disable PulseAudio.
The next topic we took up was base volumes, and whether they are useful to most end users. For those unfamiliar with the concept, we sometimes see sinks/sources where which support volume controls going to > 0dB (which is the no=attenuation point). We provide the maximum allowed gain in ALSA as the maximum volume, and suggest that UIs show a marker for the base volume.
It was felt that this concept was irrelevant, and probably confusing to most end users, and that we suggest that UIs do not show this information any more.
Relatedly, it was decided that having a per-port maximum volume configuration would be useful, so as to allow users to deal with hardware where the output might get too loud.
Our next topic of discussion was finding a way to deal with devices such as those HDMI ports where the capabilities of the device could change at run time (for example, when you plug out a monitor and plug in a home theater receiver).
A few ideas to deal with this were discussed, and the best one seemed to be David’s proposal to always have a separate card for each HDMI device. The addition of dynamic profiles could then be exploited to only make profiles available when an actual device is plugged in (and conversely removed when the device is plugged out).
It was suggested that we could split our current configuration files into three categories: core, policy and hardware adaptation. This was met with approval all-around, and the pre-existing ability to read configuration from subdirectories could be reused.
Another feature that was desired was the ability to ship multiple configurations for different hardware adaptations with a single package and have the correct one selected based on the hardware being run on. We did not know of a standard, architecture-independent way to determine hardware adaptation, so it was felt that the first step toward solving this problem would be to find or create such a mechanism. This could either then be used to set up configuration correctly in early boot, or by PulseAudio for do runtime configuration selection.
Relatedly, moving all distributed configuration to /usr/share/..., with overrides in /etc/pulse/... and $HOME were suggested.
David volunteered to implement a per-sink-input timer for accurately determining when drain was completed, rather than waiting for the period of the entire buffer as we currently do. Unsurprisingly, no objections were raised to this solution to the long-standing issue.
In a similar vein, redefining the underflow event to mean a real device underflow (rather than the client-side buffer running empty) was suggested. After some discussion, we agreed that a separate event for device underruns would likely be better.
We called it a day at this point and dispersed beer-wards.
 Our valiant attendees after a day of plotting the future of PulseAudio
Our valiant attendees after a day of plotting the future of PulseAudio
David very kindly invited us to spend a day after the conference hacking at his house in Lund, Sweden, just a short hop away from Copenhagen. We spent a short while in the morning talking about one last item on the agenda — helping to build a more seamless user experience. The idea was to figure out some tools to help users with problems quickly converge on what problem they might be facing (or help developers do the same). We looked at the Ubuntu apport audio debugging tool that David has written, and will try to adopt it for more general use across distributions.
The rest of the day was spent in more discussions on topics from the previous day, poring over code for some specific problems, and rolling out the first release candidate for the upcoming 3.0 release.
I am very happy that this conference happened, and am looking forward to being able to do it again next year. As you can see from the length of this post, there are lot of things happening in this part of the stack, and lots more yet to come. It was excellent meeting all the fellow PulseAudio hackers, and my thanks to all of them for making it.
Finally, I wouldn’t be sitting here writing this report without support from Collabora, who sponsored my travel to the conference, so it’s fitting that I end this with a shout-out to them. :)
This problem seems to bite some of our hardened users a couple of times a year, so thought I’d blog about it. If you are using grsec and PulseAudio, you must not enable CONFIG_GRKERNSEC_SYSFS_RESTRICT in your kernel, else autodetection of your cards will fail.
PulseAudio’s module-udev-detect needs to access /sys to discover what cards are available on the system, and that kernel option disallows this for anyone but root.
David has now published a tentative schedule for the PulseAudio Mini-conference (I’m just going to call it PulseConf — so much easier on the tongue).
For the lazy, these are some of the topics we’ll be covering:
Phew — and there are more topics that we probably will not have time to deal with!
For those of you who cannot attend, the Linaro Connect folks (who are graciously hosting us) are planning on running Google+ Hangouts for their sessions. Hopefully we should be able to do the same for our proceedings. Watch this space for details!
p.s.: A big thank you to my employer Collabora for sponsoring my travel to the conference.
For those of you who missed it, your friendly neighbourhood PulseAudio hackers are converging on Copenhagen in a month to discuss, plan and hack on the future of PulseAudio.
We’re doing this for the first time, so I’m super-excited! David has posted details so if this is of interest to you, you should definitely join us!
The first PulseAudio conference is approaching quickly. This is a shoutout for people who might be interested, but missed the mailinglist announcement.
The conference will be Friday 2nd November 2012, and colocated with Ubuntu Developer Summit and Linaro Connect, in Bella Center, Copenhagen.
There is no attendance fee, but you’ll need a UDS or LC registration (which are also free) to be able to get into the conference area. (Note: LC might be the safer bet here as UDS ends on Thursday)
There had been a few topics brought up on the mailinglist, but we welcome anyone who would like to contribute to constructive discussions and help to shape the future of PulseAudio!
If you would like to attend, how about you write an email to the pulseaudio-discuss mailinglist with the topic(s) you want to bring up, and maybe a small presentation with your background and interests? Of course, if you mostly want to listen in rather than bring your own topics, that’s okay too!
The audio stack in Linux/Ubuntu evolves over time. What used to be good advice is not necessarily good advice anymore. (That also means, that if you happen to read this blog post in 2019 or something, don’t trust it!)
Here are some things that people try, and sometimes they even fix the problem, but are often bad in one way or the other. Or at least, they have side effects one needs to be aware of. So – while there are valid exceptions, as a rule of thumb, don’t do the following:
A user has access to the audio card if that person is either logged in – both VT and GUI login counts, but not SSH logins, or if that user is in the “audio” group. However, on the level of access we’re talking about here, only one user has access at a time. So the typical problem scenario goes like:
I’ve written a longer article about the audio group here. In short, there are some usages for it, including that it is also the standard group name for assigning realtime priorities when used together with JACK. But don’t leave a user in the audio group unless you have a good reason.
A common way to try to get HDA Intel soundcards to work is to edit /etc/modprobe.d/alsa-base.conf and add the following line:
options snd-hda-intel model=[something]
…where [something] are values you find in some file. Contrary to official documentation, this is in most cases obsolete. In particular, avoid model=generic – that is almost guaranteed to give you trouble. In many cases, when trying different models, you will find that you might fix one thing but break another.
In fact, there is only one model to try, and that is model=auto. If your machine happen to be one of those quirked to use an older model parser, changing to model=auto can improve the situation.
Instead do:
It still happens that BIOS/UEFI assigns the wrong values to pin nodes, which causes an output or input not to work correctly. If so, I recommend trying to tweak this with hda-jack-retask.
In some cases, trying different modules can actually be okay – sometimes, these models point to lightweight fixups instead of the earlier, more heavyweight code that was used in previous kernels. (In this context, I have to mention that Takashi Iwai has done a fantastic job of converting the older models to the newer auto-parser.)
I’ve seen far too many people reporting bugs on Launchpad where they’ve been following some random blog post that tells you how to upgrade ALSA, and are having audio issues as a result. These guides are of varying quality and often come without good uninstall instructions, so you have no way to revert in case the upgrade did not solve your problem, or broke something else.
First, something not everybody is aware of: 95% of ALSA code is in the kernel, and follows the kernel’s release cycle. That means that even if “/proc/asound/version” says something that was released a year or two ago, don’t panic. It’s the kernel release that tells you how new your sound drivers are, so if you have a new kernel, and you see an ALSA release coming out, you are unlikely to gain from an upgrade.
Instead do:
In some case you do have an old kernel, and newer sound drivers can be worth a try. The Ubuntu Audio Developer’s team provides daily snapshot drivers for HDA Intel cards. Guide is available here and it also comes with proper uninstall instructions.
In the past we have also provided drivers for other cards, but due to the maintenance required to keep this up-to-date, in combination with that the vast majority of people’s bugs concern HDA Intel anyway, this support has been discontinued.
First, PulseAudio itself isn’t perfect, some of the bindings to PulseAudio aren’t perfect, and some of the drivers are not perfect in the way PulseAudio wants to use it either. So there might be valid reasons to temporarily move it out of your way, even if it would be better to actually fix the problem and submit a bug fix patch (if you’re capable of doing so).
But don’t try uninstalling the PulseAudio package, as it has far too many dependencies.
Instead do:
If you just need direct access to your sound card, you can run the “pasuspender” command. You can either run “pasuspender” (in a terminal) to make PulseAudio stay away for the duration of the application. Or if you think that’s simpler, just run “pasuspender bash” (in a terminal), start your application through the menu/dash/whatever you prefer, and when you’re done, write “exit” in the terminal.
If you need to stop the PulseAudio process completely, execute these commands:
echo autospawn=no > ~/.pulse/client.conf
pulseaudio -k
If you need PulseAudio back again, remove ~/.pulse/client.conf, then try to start an application that uses PulseAudio, and it should start automatically.
Unexpected side effects:
OSS was the standard used before ALSA came along. These days, ALSA is much better, both when it comes to hardware support, and when it comes to how much software that supports outputting sound to either sound system. OSS is also entirely unsupported, at least by Ubuntu. In addition, I’m not sure exactly how to get back to a working system after you’ve tried OSS…!
Instead do:
If you know your problem is in ALSA, either drivers or userspace, try to track down and/or fix the bug, and talk to us about it. If you’re running Ubuntu, file a bug against the alsa-driver package. You can also contact the alsa-devel mailinglist. While we won’t guarantee responses due to the high volume of bugs/traffic, we are often able to help out.
Note 1. HDA Intel cards are the built-in audio inputs and outputs on your motherboard (at least if you bought your computer after ~2006 or so). HDMI and DisplayPort audio are also HDA Intel cards, but they are covered in more detail here.
Note 2. I have had some problems with spammers posting spam comments to my blog post. I don’t want to spend too much time just reading spam and marking it as such, so I might close for comments in a relatively short period. Sorry for the inconvenience.
README file says, the configure script must be run with the CFLAGS="-ggdb3 -O0" LDFLAGS="-ggdb3" environment variables, to be able to start from the build directory.pa__init(pa_module*m) and pa__done(pa_module*m), which are called when the module is loaded and, respectively, unloaded (either by PulseAudio or because it has finished whatever it was doing). Other than these functions, PulseAudio recognises a few others that provide some information about the module (such as the author or the description). However, these functions are not generally implemented directly, but rather created through the following macros defined in pulsecore/module.h:PA_MODULE_AUTHOR(s)
PA_MODULE_DESCRIPTION(s)
PA_MODULE_USAGE(s)
PA_MODULE_VERSION(s)
PA_MODULE_DEPRECATED(s)
PA_MODULE_LOAD_ONCE(b)
pulsecore/module.h also contains the pa_module struct definition, which is explained on the Module API wiki page. One particularly relevant field of the structure is the userdata field, because it's the only way to carry information from pa__init to pa__done. This is why modules will generally define a userdata struct that contains all the relevant module data, and that is used by pa__done to free whatever memory is allocated in pa__init. This struct is also used to pass data to core hooks that handle various events.pa_module structure is the core field. This contains a pa_core struct, which is defined in pulsecore/core.h and is described on the Core API wiki page. This field is particularly relevant because it is used when creating hooks.pulsecore/hook-list.h:pa_hook_slot* pa_hook_connect(pa_hook *hook, pa_hook_priority_t prio, pa_hook_cb_t cb, void *data);
void pa_hook_slot_free(pa_hook_slot *slot);
hooks array in pa_core, which is indexed according to the pa_core_hook enum defined in pulsecore/core.h. As an example, the hook that is called after a card has been created is referred to by m->core->hooks[PA_CORE_HOOK_CARD_PUT].pa_hook_priority_t is another enum defined in pulsecore/hook-list.h and can currently take the values PA_HOOK_EARLY, PA_HOOK_NORMAL or PA_HOOK_LATE. However, these are just integers and the call can be adjusted to control the order in which hooks are run (e.g. PA_HOOK_LATE+10 will run after PA_HOOK_LATE).pa_hook_cb_t is a function pointer defined in pulsecore/hook-list.h, with the following definition:typedef pa_hook_result_t (*pa_hook_cb_t)(and the last parameter is used for whatever user data needs to be passed from the module to the hook callback function.
void *hook_data,
void *call_data,
void *slot_data);
#ifdef HAVE_CONFIG_H
#include <config.h>
#endif
#include <pulse/proplist.h>
#include <pulse/xmalloc.h>
#include <pulsecore/card.h>
#include <pulsecore/core.h>
#include <pulsecore/log.h>
#include <pulsecore/module.h>
#include "module-desktop-notifications-symdef.h"
PA_MODULE_AUTHOR("Ștefan Săftescu");
PA_MODULE_DESCRIPTION("Integration with the Desktop Notifications specification.");
PA_MODULE_VERSION(PACKAGE_VERSION);
PA_MODULE_LOAD_ONCE(TRUE);
struct userdata {
pa_hook_slot *card_put_slot;
};
static pa_hook_result_t card_put_cb(pa_core *c, pa_card *card, void* userdata) {
pa_log_info("Card detected: %s.", pa_proplist_gets(card->proplist, PA_PROP_DEVICE_DESCRIPTION));
return PA_HOOK_OK;
}
int pa__init(pa_module*m) {
struct userdata *u;
m->userdata = u = pa_xnew(struct userdata, 1);
u->card_put_slot = pa_hook_connect(&m->core->hooks[PA_CORE_HOOK_CARD_PUT], PA_HOOK_LATE, (pa_hook_cb_t) card_put_cb, u);
return 0;
}
void pa__done(pa_module*m) {
struct userdata *u;
pa_assert(m);
if (!(u = m->userdata))
return;
if (u->card_put_slot)
pa_hook_slot_free(u->card_put_slot);
pa_xfree(u);
}
Hot on the heals of the awesome PulseAudio 2.0 release, I am very please to announce Mageia 2! It's been a lot of very hard work and I inadvertently ended up doing a lot more than I had originally intended but I can't complain - while it was a lot of hard work and a massive time sink for the last few months, I certainly learned a great deal and feel I've contributed to a great user experience.So what makes Mageia magic? Well I like to think it's because we've got a great bunch of people involved - not only that, we have clear guidelines about how the whole project can never be owned by a corporate interest - it's a true community distro. If this is important to you, (and it should be!) then I encourage you to get involved and help us make it even more magic.
Not only that, but while we're a young distro we come with a rich history: Mandriva. While the corporate side of Mandriva is still somewhat struggling, the breadth of experience our contributors have is much greater than our age would normally indicate.
In terms of technology, I like to think we're a very forward facing distro. We're keen to adopt and contribute to the new "plumbing" layers being developed. Like pretty much every other distro out there, we've seen the value in this standardisation process and wholeheartedly adopted the new pid 1, systemd. Unlike some others, we've clearly stated that while Mageia 2 supports both systemd and sysvinit, Mageia 3 will focus solely on systemd. We do not see value in providing a half-hearted version of three different init systems and would much rather go "all in" and provide an excellent experience with the one that looks the strongest and offers the most compelling technical advantages. This will see us providing tools to help users administer their systems better and help with bug reports and fixes upstream too.
We also strongly support our packagers and developers contributing directly upstream. Just recently the xsettings-kde project was removed from Mageia subversion and migrated into KDE git upstream such that other distros can contribute more easily.
So for these reasons and many, many more, I feel we can continue to make the magic happen!
In terms of this release specifically, there are so many people to thank. In no particular order: Anne Nicolas, Thomas Backlund, Thierry Vignaud, Dexter Morgan, Pascal Terjan, Olivier Blin and many others on the development side, the many awesome folks in the QA team, those pesky bug reporters (some who were absolutely amazing and very understanding) and those who helped get the Artwork and Marketing side of things looking nice and slick. I'm sorry if I didn't mention you by name above, but there really are many, many lovely people involved and to thank everyone individually would just take too long! Rest assured, you are all awesome! Also thanks have to also go to the good folks involved in upstream projects. For me personally that's particularly Lennart Poettering, Kay Sievers, Michal Schmidt and Tom Gundersen (and others) from systemd and Harald Hoyer from dracut (most of whole are Redhat employees with the exception of Tom who is an Arch contributor); Arun Raghavan, Tanu Kaskinen and David Henningsson from PulseAudio; to the KDE and GNOME projects and their many, many contributors and to everyone else supporting the use of Free software - don't be owned - own it!!!









Are you:
If so, I might need your help to be able to fix it for you!
In Ubuntu 12.04 – and very likely, other recent distribution releases as well – there are at least these three audio bugs that need manual quirking for every machine. This means that you submit your hardware info in the meta-bug, I will look in that info for some ID numbers and include them in a list of devices for which a specific workaround has to be applied. We can’t apply the workaround for every device, as that could potentially cause problems for other devices.
So if you’re suffering from one of the bugs I’m describing below, I could use your help to make sure they are fixed for future releases of Ubuntu and ALSA/PulseAudio.
If you’re suffering from one of the following problems:
1) In the sound settings dialog, when you plug your headphones into the designated 3.5 mm jack, there is a “Headphones” device correctly shown, but when you unplug it, there is no “Speaker” device shown, even though you have internal speakers on your computer.
2) In the sound settings dialog, when you plug your external microphone into the designated 3.5 mm jack, there is a “Microphone” (or similar) device correctly shown, but when you unplug it, there is no “Internal Mic” device shown, even though you have an internal mic on your computer.
Then you might be suffering from bug 946232. Please look in that bug for your device in that list, and if it is not there, try the workaround and if it’s working, add your alsa-info as suggested in the bug. Thanks!
If you have a USB headset, or another USB device that does not have any S/PDIF output, but yet sometimes there is an extra device called “Digital Output (S/PDIF)” for that device in Sound Preferences. If so, you’re likely suffering from bug 1002952. At the time of this writing there are also a few devices that are on their way to becoming fixed, if you have one of these, please help out with testing the proposed repository. There is more information in bug 1002952 about that.
In this case, you have an internal mic showing up, but it seems not to work: it’s either completely silent, or you can possibly pick a very small sound, with much background noise, even though you have set gain to maximum.
There is something you could try. Install the pavucontrol application, start it and go to the “Input Devices” tab. Unlock the channels (click the keylock icon), then mute the right channel while keeping the left channel at the volume you want.
If the internal mic is now working correctly, you have an inverted internal mic, so that your right channel cancels out the left one. (Why the hardware is constructed that way is beyond me.)
This seems to be most common on Acer Aspire laptops, but I’ve seen them on other laptops as well, and fixing these are more of a long term project as they are non-trivial kernel patches. So far I’ve created a patch for Thinkpad U300s. Anyway, I would like to track the remaining ones in bug 1002978, so please add your system there according to the instructions.
Last but not least – thanks in advance for helping Ubuntu, as well as the greater Linux ecosystem (I’ll make sure that the patches pushed into Ubuntu gets upstream as well)!
Horay! I participate in this year’s Google Summer of Code and I’ll be involvled in PulseAudio community to help enhance the logging and testing facilities.
Let me first introduce what’s GSoC (Google Summer of Code), it’s a project hosted by Google every year to motivate students to be engaged in open source projects. Students will have a meaningful summer and be paid for their hard coding work. :)
Then PulseAudio project. If you’re using a modern Linux desktop, then chances are that you’re already using this software. It’s the component which helps to mix all the sounds from other applications and then output them into your speakers or headphones.
Finally me :) I’m a student from East China Normal University. Technically speaking, I’m not majoring in computer science, nor anything related to it. But I’m inspired by my friends and now I’m happy to say that I could CODE! This is the coolest skill, that is, I can make almost anything into reality.
I’m so lucky to be chosen into PulseAudio community. I’d love to thanks all the developers in this community. My mentor Arun, and the maintainer Colin, and Tanu even had a full code review on my proof of concept of circular log buffering patch!
Well, let me share some tips how you would be better selected in GSoC.
First, start early! Early birds catches the worms. Each year’s schedule is quite similar, find out last year’s accepted projects and see which one interests you most. This whole list is quite long, so start early to find out your interests!
Second, be involved in the community. Once you’ve found one project, the first thing you should do is to be invovled in the community. Being involved has different meanings, the first step is of course to download the software and have a try, be a user! And then be a tester. Then, you can find out from its website to see how to setup your developement environment. Sign up for the mailing list, or even hang out in its IRC channel.
Third, do your homework. Now it comes the hard part. :) After some tests and uses, you may wonder, “hey, this could be enhanced!” or “I would this feature in another way!”. That’s a good sign, this means you have your own opinion on what the project should be shaped. Then start small and write a simple demo to show you are ABLE to do this project. In my application, I spent about one week to write the circular log buffer demo and it turns out to be useful of getting myself faimilar with its internals.
Now here are some words about this blog. According to the advice from Colin, I’m setting this blog up to mainly track my status of this summer project. However, possibly this blog would have more technically contents later on with more engagement in open source community. It’s a good start, isn’t it? :D

That’s right, it’s finally out! Thanks go out to all our contributors for the great work (there’s too many — see the shortlog!). The highlights of the release follow. Head over to the announcement or release notes for more details.
Dynamic sample rate switching by Pierre-Louis Bossart: This makes PulseAudio even more power efficient.
Jack detection by David Henningsson: Separate volumes for your laptop speakers and headphones, and more stuff coming soon.
Major echo canceller improvements by me: Based on the WebRTC.org audio processing library, we now do better echo cancellation, remove the need to fiddle with the mic volume knob and have fixed AEC between laptop speakers and a USB webcam mic.
A virtual surround module by Niels Ole Salscheider: Try it out for some virtual surround sound shininess!
Support for Xen guests by Giorgos Boutsiouki: Should make audio virtualisation in guests more efficient.

Special thanks from me to Collabora for giving me some time for upstream work.
Packages are available on Gentoo, Arch, and probably soon on other distributions if they’re not already there.
There's one feature In the upcoming Fedora 17 release that is immensly useful but very little known, since its feature page 'ckremoval' does not explicitly refer to it in its name: true automatic multi-seat support for Linux.
A multi-seat computer is a system that offers not only one local seat for a user, but multiple, at the same time. A seat refers to a combination of a screen, a set of input devices (such as mice and keyboards), and maybe an audio card or webcam, as individual local workplace for a user. A multi-seat computer can drive an entire class room of seats with only a fraction of the cost in hardware, energy, administration and space: you only have one PC, which usually has way enough CPU power to drive 10 or more workplaces. (In fact, even a Netbook has fast enough to drive a couple of seats!) Automatic multi-seat refers to an entirely automatically managed seat setup: whenever a new seat is plugged in a new login screen immediately appears -- without any manual configuration --, and when the seat is unplugged all user sessions on it are removed without delay.
In Fedora 17 we added this functionality to the low-level user and device tracking of systemd, replacing the previous ConsoleKit logic that lacked support for automatic multi-seat. With all the ground work done in systemd, udev and the other components of our plumbing layer the last remaining bits were surprisingly easy to add.
Currently, the automatic multi-seat logic works best with the USB multi-seat hardware from Plugable you can buy cheaply on Amazon (US). These devices require exactly zero configuration with the new scheme implemented in Fedora 17: just plug them in at any time, login screens pop up on them, and you have your additional seats. Alternatively you can also assemble your seat manually with a few easy loginctl attach commands, from any kind of hardware you might have lying around. To get a full seat you need multiple graphics cards, keyboards and mice: one set for each seat. (Later on we'll probably have a graphical setup utility for additional seats, but that's not a pressing issue we believe, as the plug-n-play multi-seat support with the Plugable devices is so awesomely nice.)
Plugable provided us for free with hardware for testing multi-seat. They are also involved with the upstream development of the USB DisplayLink driver for Linux. Due to their positive involvement with Linux we can only recommend to buy their hardware. They are good guys, and support Free Software the way all hardware vendors should! (And besides that, their hardware is also nicely put together. For example, in contrast to most similar vendors they actually assign proper vendor/product IDs to their USB hardware so that we can easily recognize their hardware when plugged in to set up automatic seats.)
Currently, all this magic is only implemented in the GNOME stack with the biggest component getting updated being the GNOME Display Manager. On the Plugable USB hardware you get a full GNOME Shell session with all the usual graphical gimmicks, the same way as on any other hardware. (Yes, GNOME 3 works perfectly fine on simpler graphics cards such as these USB devices!) If you are hacking on a different desktop environment, or on a different display manager, please have a look at the multi-seat documentation we put together, and particularly at our short piece about writing display managers which are multi-seat capable.
If you work on a major desktop environment or display manager and would like to implement multi-seat support for it, but lack the aforementioned Plugable hardware, we might be able to provide you with the hardware for free. Please contact us directly, and we might be able to send you a device. Note that we don't have unlimited devices available, hence we'll probably not be able to pass hardware to everybody who asks, and we will pass the hardware preferably to people who work on well-known software or otherwise have contributed good code to the community already. Anyway, if in doubt, ping us, and explain to us why you should get the hardware, and we'll consider you! (Oh, and this not only applies to display managers, if you hack on some other software where multi-seat awareness would be truly useful, then don't hesitate and ping us!)
Phoronix has this story about this new multi-seat support which is quite interesting and full of pictures. Please have a look.
Plugable started a Pledge drive to lower the price of the Plugable USB multi-seat terminals further. It's full of pictures (and a video showing all this in action!), and uses the code we now make available in Fedora 17 as base. Please consider pledging a few bucks.
Recently David Zeuthen added multi-seat support to udisks as well. With this in place, a user logged in on a specific seat can only see the USB storage plugged into his individual seat, but does not see any USB storage plugged into any other local seat. With this in place we closed the last missing bit of multi-seat support in our desktop stack.
With this code in Fedora 17 we cover the big use cases of multi-seat already: internet cafes, class rooms and similar installations can provide PC workplaces cheaply and easily without any manual configuration. Later on we want to build on this and make this useful for different uses too: for example, the ability to get a login screen as easily as plugging in a USB connector makes this not useful only for saving money in setups for many people, but also in embedded environments (consider monitoring/debugging screens made available via this hotplug logic) or servers (get trivially quick local access to your otherwise head-less server). To be truly useful in these areas we need one more thing though: the ability to run a simply getty (i.e. text login) on the seat, without necessarily involving a graphical UI.
The well-known X successor Wayland already comes out of the box with multi-seat support based on this logic.
Oh, and BTW, as Ubuntu appears to be "focussing" on "clarity" in the "cloud" now ;-), and chose Upstart instead of systemd, this feature won't be available in Ubuntu any time soon. That's (one detail of) the price Ubuntu has to pay for choosing to maintain it's own (largely legacy, such as ConsoleKit) plumbing stack.
Multi-seat has a long history on Unix. Since the earliest days Unix systems could be accessed by multiple local terminals at the same time. Since then local terminal support (and hence multi-seat) gradually moved out of view in computing. The fewest machines these days have more than one seat, the concept of terminals survived almost exclusively in the context of PTYs (i.e. fully virtualized API objects, disconnected from any real hardware seat) and VCs (i.e. a single virtualized local seat), but almost not in any other way (well, server setups still use serial terminals for emergency remote access, but they almost never have more than one serial terminal). All what we do in systemd is based on the ideas originally brought forward in Unix; with systemd we now try to bring back a number of the good ideas of Unix that since the old times were lost on the roadside. For example, in true Unix style we already started to expose the concept of a service in the file system (in /sys/fs/cgroup/systemd/system/), something where on Linux the (often misunderstood) "everything is a file" mantra previously fell short. With automatic multi-seat support we bring back support for terminals, but updated with all the features of today's desktops: plug and play, zero configuration, full graphics, and not limited to input devices and screens, but extending to all kinds of devices, such as audio, webcams or USB memory sticks.
Anyway, this is all for now; I'd like to thank everybody who was involved with making multi-seat work so nicely and natively on the Linux platform. You know who you are! Thanks a ton!
Derek Foreman has finally written up a nice blog post about his Androgenizer tool, which we’ve used for porting PulseAudio, GStreamer, Wayland, Telepathy and most of their dependencies to Android.
If you’ve got an autotools-based project that you’d like to build on Android, whether on the NDK or system-wide this is really useful.
Some of you might’ve noticed that there has been a bunch of work happening here at Collabora on making cool open source technologies such as GStreamer, Telepathy, Wayland and of course, PulseAudio available on Android.
Since my last blog post on this subject, I got some time to start looking at replacing AudioFlinger (recap: that’s Android’s native audio subsystem) with PulseAudio (recap: that’s the awesome Linux audio subsystem). This work can be broken up into 3 parts: playback, capture, and policy. The roles of playback and capture are obvious. For those who aren’t aware of system internals, the policy bits take care of audio routing, volumes, and other such things. For example, audio should play out of your headphones if they’re plugged in, off Bluetooth if you’ve got a headset paired, or the speakers if nothing’s plugged in. Also, depending on the device, the output volume might change based on the current output path.
I started by looking at solving the playback problem first. I’ve got the first 80% of this done (as we all know, the second 80% takes at least as long ;) ). This is done by replacing the native AudioTrack playback API with a simple wrapper that translates into the libpulse PulseAudio client API. There’s bits of the API that seem to be rarely used(loops and markers, primarily), and I’ve not gotten around to those yet. Basic playback works quite well, and here’s a video showing this. (Note: this and the next video will be served with yummy HTML5 goodness if you enabled the YouTube HTML5 beta).
(if the video doesn’t appear, you can watch it on YouTube)
Users of PulseAudio might have spotted that this now frees us up to do some fairly nifty things. One such thing is getting remote playback for free. For a long time now, there has been support for streaming audio between devices running PulseAudio. I wrote up a quick app to show this working on the Galaxy Nexus as well. Again, seeing this working is a lot more impressive than me describing it here, so here’s another video:
(if the video doesn’t appear, you can watch it on YouTube)
This is all clearly work in progress, but you can find the code for the AudioTrack wrapper as a patch for now. This will be a properly integrated tree that you can just pull and easily integrate into your Android build when it’s done. The PA Output Switcher app code is also available in a git repository.
I’m hoping to be able to continue hacking on the capture and policy bits. The latter, especially, promises to be involved, since there isn’t always a 1:1 mapping between AudioFlinger and PulseAudio concepts. Nothing insurmountable, though. :) Watch this space for more updates as I wade through the next bit.
It has been way too long since my last status update on systemd. Here's another short, incomprehensive status update on what we worked on for systemd since then.
We have been working hard to turn systemd into the most viable set of components to build operating systems, appliances and devices from, and make it the best choice for servers, for desktops and for embedded environments alike. I think we have a really convincing set of features now, but we are actively working on making it even better.
Here's a list of some more and some less interesting features, in no particular order:
Much of the stuff above is already available in Fedora 15 and 16, or will be made available in the upcoming Fedora 17.
And that's it for now. There's a lot of other stuff in the git commits, but most of it is smaller and I will it thus spare you.
I'd like to thank everybody who contributed to systemd over the past years.
Thanks for your interest!
Disclaimer: Planet PulseAudio automatically reposts blog entries from the PulseAudio community. Entries on this page are owned by their authors. We do not edit, endorse or vouch for the contents of individual posts.
Last updated: March 04, 2021 12:00 PM All times are UTC.
Powered by: ![]()
Design and layout based on Planet GNOME with some help from Laura Suárez





{kind=link}
{kind=link}