![]()
| Home | About | Community | Download | Documentation | Planet |
Client API for node-based routing management
Querying nodes and their connections
Clients should be able find out what nodes exist and how they are connected to each other. I like to picture the nodes as two vertical rows, the input nodes on the left and the output nodes on the right:
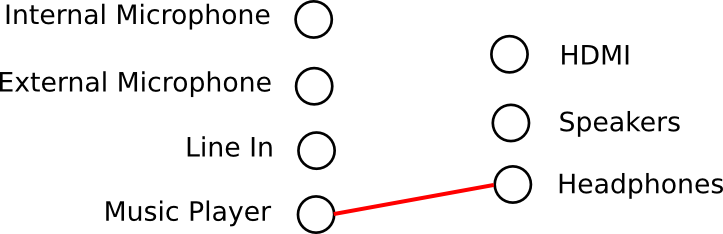
That picture represents a typical case on my laptop: there are several device nodes, and a music player stream node that is connected to the headphone node.
Querying the nodes can be done like any other object:
/** Routing node information. Please note that this structure can be extended
* as part of evolutionary API updates at any time in any new release.
*
* \since 5.0 */
typedef struct pa_node_info {
/** The index of this node. */
uint32_t index;
/** The name of this node. While one name can refer to only one node at any
* given time, the same name can still refer to multiple nodes over time,
* and the same node may have a different name e.g. after server restart.
* This means that nodes don't have any identifier that could be e.g. saved
* to disk for referring to the same node later. There may be some nodes in
* the future that have a fixed name, but currently there are none. */
const char *name;
/** The human-readable description of this node. This is localized and
* suitable to be shown in user interfaces as the label for this node. */
const char *description;
/** The direction of this node. */
pa_direction_t direction;
/** Connections to other nodes. The connections are represented by an array
* of node indexes. */
uint32_t *connections;
/** Size of the connections array. */
unsigned n_connections;
} pa_node_info;
/** Callback prototype for pa_context_get_node_info_by_name() and friends.
* \since 5.0 */
typedef void (*pa_node_info_cb_t)(pa_context *c, const pa_node_info *info, int eol, void *userdata);
/** Get information about a node by its name. \since 5.0 */
pa_operation *pa_context_get_node_info_by_name(pa_context *c, const char *name, pa_node_info_cb_t cb, void *userdata);
/** Get information about a node by its index. \since 5.0 */
pa_operation *pa_context_get_node_info_by_index(pa_context *c, uint32_t idx, pa_node_info_cb_t cb, void *userdata);
/** Get a list of all nodes. \since 5.0 */
pa_operation *pa_context_get_node_info_list(pa_context *c, pa_node_info_cb_t cb, void *userdata);
Monitoring node state
Nodes have mutable state (for example, their connections), so there needs to be a way to get notified about state changes. This can be handled with the subscription system as usual. pa_subscription_mask_t and pa_subscription_event_type_t need to be extended:
/** Subscription event mask, as used by pa_context_subscribe() */
typedef enum pa_subscription_mask {
...
PA_SUBSCRIPTION_MASK_NODE = 0x0400U,
/**< Node events. \since 5.0 */
PA_SUBSCRIPTION_MASK_ALL = 0x06ffU /* The deprecated autoload events (0x0100) are not included. */
/**< Catch all events */
} pa_subscription_mask_t;
/** Subscription event types, as used by pa_context_subscribe() */
typedef enum pa_subscription_event_type {
...
PA_SUBSCRIPTION_EVENT_NODE = 0x000aU,
/**< Event type: Node. \since 5.0 */
...
} pa_subscription_event_type_t;
Adding and removing connections
A GUI for managing node connections might work so that the user creates and removes connections one at a time and the GUI program immediately sends a connect/disconnect command to the server after each user action. Another possibility is that the GUI lets the user do the connections, and only after selecting "apply" the GUI program will send the connection updates to the server. The question is: should the API have functions for adding and removing only a single connection at a time, or should the API work so that the client sets the whole connection list, or should both be possible?
I would prefer to support at least single connection adding/removal, because I imagine it would match more closely the way UIs usually work (I find it unlikely that UIs would have an "apply" button), and it also avoids a race condition: if two clients add different connections for a node simultaneously, it works fine (both connections get added) if the command is "add connection", but only one of the clients would win if they would have to use command "set the connection list". If changing multiple connections in one go is important, the race could be avoided also by having a batch command for applying multiple add/remove commands. It's of course possible to support all of these: "add connection", "remove connection", "batched add/remove" and "set the connection list". I would start with just "add connection" and "remove connection" commands for simplicity.
Proposed API:
/** Connect two nodes together. The nodes to connect can be identified by their
* names or their indexes (in order to use index based identification, just
* convert the index number to a string). One of the nodes must be an input
* node and the other must be an output node, but it doesn't matter in which
* order the nodes are given. \since 5.0 */
pa_operation *pa_context_add_node_connection(
pa_context *c,
const char *node_a,
const char *node_b,
pa_context_success_cb_t cb,
void *userdata);
/** Disconnect two nodes. The nodes to disconnect can be identified by their
* names or their indexes (in order to use index based identification, just
* convert the index number to a string). \since 5.0 */
pa_operation *pa_context_remove_node_connection(
pa_context *c,
const char *node_a,
const char *node_b,
pa_context_success_cb_t cb,
void *userdata);
What if the last connection of a stream node is removed? Does the removal fail? Is the stream killed, because streams must always be connected to some sink or source? I think the stream should be moved to a null sink/source even in absence of any policy modules (this implies adding null sink and source functionality to the core, because I don't think we want the core to load any modules). The null sink wouldn't be exposed as a node, and therefore the connection between the stream and the null sink wouldn't be visible in the node API (it would still be visible in the lower level API as a sink).
Moving connections
Moving a connection, for example a sink input from one sink to another, is a bit different than just "remove connection" and "add connection" executed sequentially. If moving was implemented as "remove and add", in what state would the sink input be after the "remove connection" command? It might be routed to a null sink. That's not ideal. Routing the sink input to an intermediate target adds delay and will likely cause some audio to be lost. Therefore, I think there needs to be a distinct "move connection" command.
Proposed API:
/** Move a node connection. This operation involves three nodes: A, B and C.
* The move operation moves a connection between A and B so that after
* a successful move operation A and B are not connected any more, but A and C
* are.
*
* The nodes can be identified by their names or their indexes (in order to use
* index based identification, just convert the index number to a string).
* \since 5.0 */
pa_operation *pa_context_move_node_connection(
pa_context *c,
const char *node_a,
const char *node_b,
const char *node_c,
pa_context_success_cb_t cb,
void *userdata);
Default and explicit connections
The Intel folks have come up with concepts called "default route" and "explicit route". This was probably discussed to some extent in the PulseConf, but as a reminder, here's an attempt at defining those terms. A "default route" is a connection to/from a node that is completely driven by automatic routing policy (or it could be determined just by the default sink/source if nothing fancier is implemented by modules). An "explicit route" is a connection that has been requested by the user. I prefer the word "connection" over "route", so I will call the concepts "default connection" and "explicit connection".
Even though explicit connections are generally "less automatic" than default connections, there can still be a fair bit of automation going on with explicit routes. For example, remembering and restoring user routing requests in the style of stream-restore is better implemented as explicit connections than default connections.
A good routing policy will distinguish between node connections that are created by the user and connections that are created without the user requesting them. So the "default connection" and "explicit connection" concepts will anyway exist. It is arguable, however, whether those concepts should be visible in the client API (I'm in favour of having them visible).
Proposed API for representing the information about explicit and default connections:
typedef struct pa_node_info {
...
/** Explicit connections to other nodes. The connections are represented by
* an array of node indexes. */
uint32_t *explicit_connections;
/** Size of the explicit_connections array. */
unsigned n_explicit_connections;
/** Are the default connections enabled? If this is zero, then the
* connections listed in own_default_connections don't actually exist, they
* only represent connections that would exist if default connections were
* enabled. This doesn't affect the connections in
* other_default_connections. */
int default_connections_enabled;
/** This node's own default connections. */
uint32_t *own_default_connections;
/** Size of the own_default_connections array. */
unsigned n_own_default_connections;
/** Other nodes' default connections to this node. */
uint32_t *other_default_connections;
/** Size of the other_default_connections array. */
unsigned n_other_default_connections;
} pa_node_info;
It is possible that one connection is both explicit and default. An example:
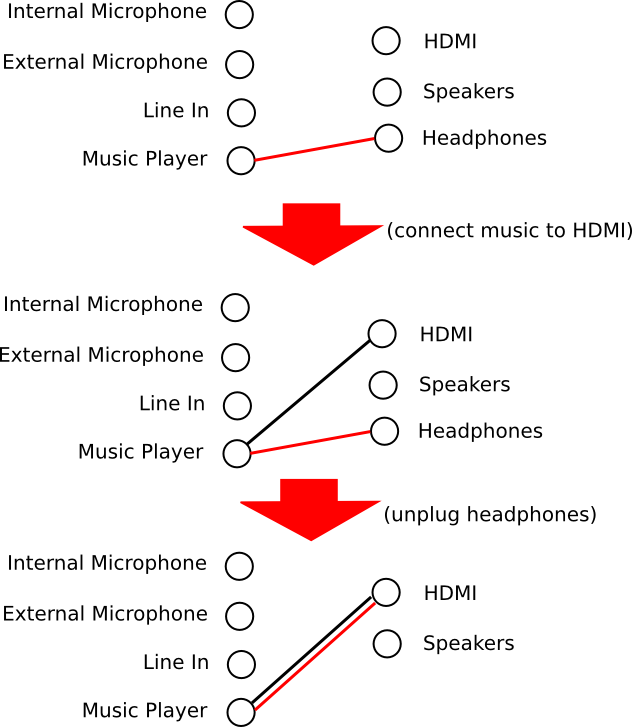
Here my music is first connected to the headphones via a default connection (red). Then I decide to add a connection also to the HDMI output, it becomes an explicit connection (black). Then I unplug the headphones, and the default route changes to the HDMI output, so now the connection between the headphones and the HDMI output is both a default connection and an explicit connection.
One thing to consider is whether the default connections should be visible to the clients also when default connections are disabled. In the proposal I have chosen to have them visible, because it's extra information that is potentially useful to clients. The drawback is that maintaining the list of default connections also when the default connections aren't enabled may cause extra work for the routing policy code in the server (the amount of work may be trivial, I don't know).
Enabling and disabling default connections
There should be a command for enabling/disabling default connections for a node.
/** Enable or disable default connections of a node. The node can be
* identified by its names or index (in order to use index based
* identification, just convert the index number to a string). \since 5.0 */
pa_operation *pa_context_enable_node_default_connections(
pa_context *c,
const char *node,
int enable,
pa_context_success_cb_t cb,
void *userdata);
Moving or removing default connections
If a connection is both default and explicit, the client can, at least in theory, want to move or remove only the explicit part of it, so after the move or remove operation, the default connection would still exist as before. Another, more likely possibility is that the client wants to move or remove the connection completely. Moving or removing a default connection is not a valid operation, however, so this actually implies disabling the default connections entirely. The question is: should the client API support both cases, or should it be always implied that moving or removing a default connection will disable default connections entirely for the node? The move and remove operations could accept a flag describing the client intention: PA_NODE_REMOVE_EXPLICIT_ONLY. If that flag was set, the operation would never implicitly disable default connections, otherwise default connections would get disabled if the connection being removed was a default connection. The flag would be useful also for handling a race condition: if the client thinks that a connection is only an explicit connection when it removes it, and the default routing changes while the remove command is on its way from the client to the server, the default routing wouldn't get disabled by accident if the flag was set.
Another solution would be to never do implicit disabling of default connections. If a client wanted to move a connection that was currently a default connection, it would have to first convert the default connection to an explicit one (that is, add an explicit connection to the old destination, then disable default connections), and then move the explicit connection to the new destination.
I'm in favour of adding the flag argument to pa_context_move_node_connection() and pa_context_remove_node_connection(), because the alternative is very inconvenient for applications (especially with an asynchronous API with callbacks it's much nicer to send only one command than to execute three commands in sequence).
Getting node index from pa_stream
It's probably a good idea to make it possible to query the node index from pa_stream.
/** Return the node index of this stream. Returns PA_INVALID_INDEX if the
* stream doesn't have an associated node. \since 5.0 */
uint32_t pa_stream_get_node_index(pa_stream *s);
Defining the initial node when creating streams
Currently, if a client wants to choose the initial routing target when creating a stream, it must set the dev parameter of pa_stream_connect_playback()/pa_stream_connect_record(). The dev parameter is currently defined to be the name of the sink or source, which is not nice if the client wants to handle routing at the node level. This is easily solved, however: since all sinks, sources and nodes share the same namespace, we could allow node names to be passed as the dev parameter without any ambiguity. There's one problem, though: the client might want to specify multiple targets. Should this be allowed? I suppose it would be pretty easy to handle: the object names can't contain spaces or commas, so we could allow the dev string to be a space or comma separated list of names.
Mapping sinks, sources, ports and streams to nodes
The pa_card_port_info, pa_sink_info, pa_source_info, pa_sink_input_info and pa_source_output structs should contain the index of the associated node (if any).
Routing groups
Rough ideas:
- node can exist without being a part of a routing group
- default connections are defined by the routing group, so a node without a routing group will have no default connections
- all nodes in a group will have the same connections
- enabling or disabling default connections is a group-wide operation
- changing the connections of an individual node detaches the node from its group
- a node can match multiple routing groups, but it can be part of only one at a time
- clients can change the group of a node? (only matching groups would be allowed)
- routing groups are matched in priority order
- clients can change the priorities? (required for making group changes persistent)
- streams created with non-default routing will be created without any associated group
- ungrouped streams can be grouped (if they match any routing groups)
I'm starting to think that exposing the routing groups in the public API isn't a good idea, because it makes things a lot more complex for applications, and it limits freedom at the server side.
TODO:
- pa_context_edit_connections()
- connection objects